Deterministic vs. Probabilistic: Does your process actually need GenAI?

Most enterprise AI failures don’t start with bad code or dirty databases. They start with a single, unasked question during the initial steering committee: do we need a deterministic solution, or a probabilistic one?
Lately, I’ve been reading a lot of posts and articles related to this topic, and all of them where very focused on defending AI like if authors were getting paid from the Vendors themselves. Writing disclaimers everywhere like AI may make mistakes. Double-check all generated code doesn’t absolve anyone from paying a fair price to use the technology.
A distinction between Deterministic and Probabilistic is fundamental. It’s the main point of the shift. In operations and technology, the most efficient and elegant solutions are born from the quality of the questions we ask at the beginning, not from the novelty of the licenses we purchase.
This is the first episode of Pragmatic AI for Operations, a series dedicated to bridging the gap between GenAI hype and the physical reality of the business.
When a company approaches digital transformation, the executive team is flooded with vendor presentations pitching autonomous agents and conversational ERPs. The pressure to innovate is intense and we all can feel it. Yet, in the rush to adopt the latest technology, organizations consistently skip the foundational triage.
If you want to ground this paradigm shift in the real world, step onto the production line during a shift change.
An operator is trying to close a complex production order for customized valves, but a component is missing from the Bill of Materials. Someone suggests feeding the order history into an LLM to “predict” the missing part based on past configurations.
The thing is that the operator doesn’t need a statistical prediction of what the part might be. They need the exact, deterministic engineering specification approved by the technical department, because the wrong valve installed today means a problem in the field tomorrow.
When you transition from PowerPoint presentations to the production line, you realize that enterprise software is divided by a fundamental boundary: the divide between the deterministic core and the probabilistic edge.
If you ignore this boundary believe me, you’ll spend a considerable amount of your budget building expensive systems that won’t get you anywhere but consequently stall your operations.
Logic vs. Probability
To build a functional architecture, we must understand the core technology. Enterprise systems have historically been built on deterministic logic.
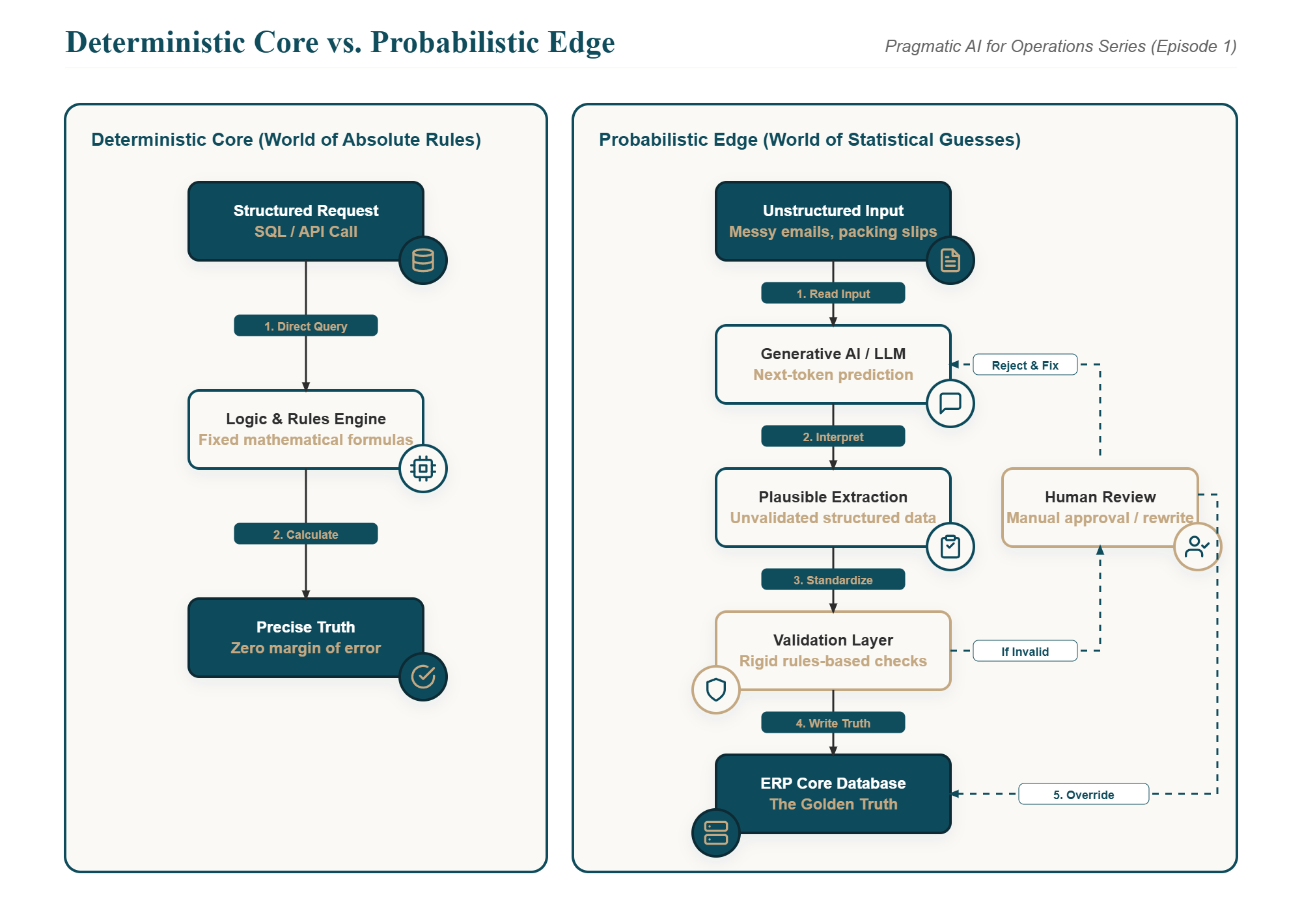
A deterministic system is a world of fixed rules. If the input is A, the output must be B. If you query the database for the stock level of a critical spare part in your ERP‘s inventory table, the system executes a standard SQL query and returns an exact mathematical figure.
In this world, there’s no space for interpretation. If the system calculates that you have forty-nine valves in stock, and the assembly line requires fifty, the process stops.
A probabilistic system, such as a Generative AI model, operates on an entirely different set of rules. It doesn’t calculate mathematical truths. It predicts the most statistically likely sequence of words based on its training data.
An LLM doesn’t actually know that 100 minus 10 equals 90. It’s simply seen that sequence of characters enough times in its training sets to predict that 90 is the correct response to that specific prompt.
This distinction may seem like a small detail, but it determines whether you build a functional architecture or an expensive nightmare. Both paradigms are powerful. The disaster begins when you deploy the wrong one for the job.
Don’t forget: when you use a probabilistic model to handle deterministic tasks, you’re introducing a margin of error into a space that demands absolute precision.
The Hallucination on the Production Line
Let’s look at how this plays out in the real world of manufacturing.
Imagine implementing an LLM to dynamically optimize production routing. The goal is to read machine breakdown logs and automatically reschedule open production orders to alternative work centers in your MES.
A primary CNC machine breaks down.
The LLM reads the maintenance log and sees an urgent batch of titanium components scheduled for tomorrow. It needs to find an alternative routing.
Based on its training data, it knows that similar components are sometimes processed on the older, secondary milling machine. So, it dynamically updates the production order and sends the titanium batch there.
But the LLM doesn’t understand physics. It doesn’t check the strict limits of the secondary machine; it simply predicts the most likely next step.
The disaster becomes now silent.
The night shift operator assumes the system knows what it’s doing and loads the titanium. The older mill, lacking the necessary torque for this specific alloy, shatters its tooling within minutes, destroying the raw material and taking a second machine offline.
The technology executed the task no doubt about it: but it used statistical probability to override a hard engineering constraint.
When an algorithm guesses a physical constraint, you need to consider there’s a systemic risk injected directly into your operations.
But the failure here was not the technology itself. It was the architectural decision to deploy a probabilistic tool in a space that demands deterministic precision.
SQL vs. The 70-Billion Parameter Model
The true architectural challenge is knowing exactly when to deploy a billion parameter language model, and when to rely on a 3ms SQL query. Especially now where people seems to use GenAI even to schedule an appointment in their calendar while having the smartphone on their hands with the calendar app already opened. Funny moments to be alive.
Now, consider safety stock calculation. It’s a well-defined mathematical formula that requires exact data points: historical consumption, supplier lead times, service level targets. The logic is fixed, the inputs are structured, and the output demands absolute precision.
An LLM adds nothing here. A language model doesn’t execute mathematical formulas. It predicts text sequences. Feeding structured numerical data into a probabilistic engine to obtain a result that a deterministic query can return in three milliseconds is the equivalent of hiring a professional novelist to balance your financial ledger. Of course, we will see over the next episode that an Agent on the other hand can give the LLM the tools he requires to complete the task, but really: that it make sense when there’s a far more better solution already available to solve the task?
The rule of thumb is simple: when the logic is fixed and the output requires precision, there is no need for a language model. Save your budget for the problems that actually require cognitive flexibility.
Tracing the Operational Boundary
So, where does Generative AI actually belong in operations?
The answer lies at the messy, unstructured edges of your business.
The physical world of logistics is filled with unstructured chaos. Suppliers send packing slips in hundreds of different formats, some with hand-written scribbles in the margins. Customers send unstructured emails with vague descriptions of the parts they want to order.
A classic deterministic system struggles with this mess. If an incoming email doesn’t match a rigid EDI format, the system rejects it, forcing a human operator to copy and paste the details manually.
This is where the probabilistic edge shines.
You can use an LLM to read the messy, unstructured email or scan the crumpled delivery note. The model is exceptional at extracting the key entities, standardizing the terms, and translating the chaotic human communication into a clean, standardized data format.
But once the data is standardized, the AI must step back.
That structured file cannot write directly to your database. It must be handed over to an integration layer, the deterministic core of your ERP. That layer uses standard rules to check if the item exists, if the customer has enough credit, and if the quantities make mathematical sense before the transaction is actually recorded.
The LLM reads the chaos; the database writes the truth.
Decoupling the Architecture
If your company is evaluating AI solutions, you can filter the market hype by applying a straightforward filter.
Where the data is already structured and precision is non-negotiable, rely on deterministic code. Where the input is messy, unstructured, and human, let a probabilistic model do the heavy lifting of interpretation.
Neither paradigm replaces the other. The real architectural challenge is decoupling the layers so they can coexist cleanly. Any LLM operating at the edge of your systems must pass its output through a rigid, rules-based validation layer before a single line of data is written to your ERP.
The next step for any organization serious about this integration is to map its own processes against this boundary. Identify where your data is structured and where it is chaotic. Draw the line. Then build the validation layer that connects the two worlds without letting one contaminate the other.
This is just the foundation. In the next episode of Pragmatic AI for Operations, we will move deeper into the architecture and explore the difference between a stateless language model and an autonomous agent, and understand the shift from reactive prompts to autonomous goals.
Written by Andrea Guaccio
June 25, 2026