Generativ BI: Att prata med dina data

(Del 2 av serien: ERP-intelligensutvecklingen: Från data till agenter)
I del 1definierade vi taxonomin.
Vi fastställde att GenAI är "assistenten" som förstår sammanhang. Men innan denna assistent kan börja göra saker (som den framtida Agentic AI) måste den först bemästra en enklare, men revolutionerande färdighet: att svara på frågor om dina data.
För att bygga den nödvändiga grunden för framtidens autonoma agentermåste vi först åtgärda ett trasigt gränssnitt: användarupplevelsen av data.
Standardgränssnittet för ERP-data är Dashboard. Även om moderna BI-verktyg är kraftfulla skapar de ofta ett gap mellan skaparen (som skapar rapporten) och konsumenten (som läser den). Om en CEO frågar: "Varför minskar marginalen i Italien?"visar dashboarden siffran. För att hitta grundorsaken måste användaren ofta filtrera, gå djupare eller – om den specifika uppdelningen inte var förbyggd – be en analytiker att skapa en ny vy.
Generativ BI (GenBI) överbryggar detta gap. Det flyttar paradigmet från att konfigurera rapporter till att kommunicera med realtidsdata.
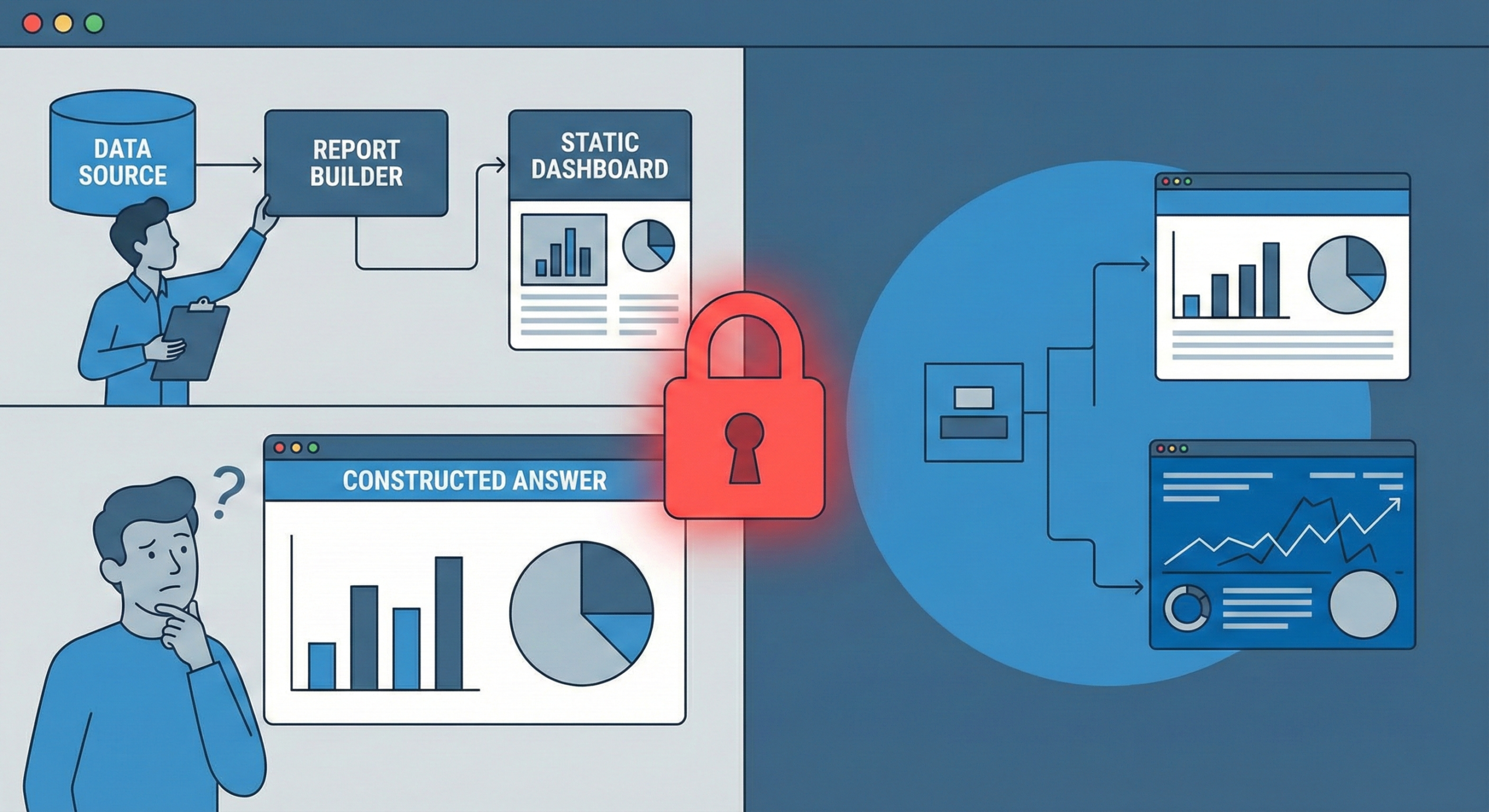
Begränsningarna med statisk BI
Traditionell Business Intelligence bygger på en modell med ”konstruerat svar” :
- Analytikern förutser affärsfrågor (t.ex. ”Försäljning per region”).
- De bygger en rapport eller pivottabell.
- Användaren konsumerar det.
Begränsningen: Även om avancerade användare kan ändra dessa rapporter, saknar affärsanvändare ofta tid eller teknisk säkerhet för att göra det. När de har en fråga som inte täcks av de befintliga filtren –"Visa mig försäljning per region, men exkludera de utgående artiklarna från tredje kvartalet"– stannar flödet. De är beroende av rapportens design.
"Text-till-SQL"-revolutionen
GenBI låter alla användare söka efter data med hjälp av naturligt språk, vilket ersätter behovet av dra-och-släpp-funktioner med en chattfält. Detta bygger på en specifik AI-arkitektur som kallas Text-to-SQL.
När man använder ett GenBI-gränssnitt (som Wren AI eller funktionerna för frågesökning med naturligt språk i Infor OS) ändras arbetsflödet:
- Uppmaning: Användaren frågar: ”Visa mig öppna inköpsordrar för leverantören 'SteelCorp' som är försenade med mer än 5 dagar.”
- Översättningen (LLM): Den stora språkmodellen analyserar begäran.
- Det semantiska lagret (nyckeln): AI:n refererar till ett "semantiskt lager" (en affärsordlista som mappar termer till databastabeller). Den förstår att "Leverantör" refererar till tccom100 och "Försenad" betyder att jämföra planerat mottagningsdatum mot idag.
- Utförandet: Den genererar en exakt SQL-fråga, kör den mot datasjön och returnerar live-resultatet.
Varför det "semantiska lagret" är viktigt: Utan ett semantiskt lager (som Data Fabric i Infor OS) kan GenBI inte fungera tillförlitligt. Om AI:n inte vet specifikt hur ERP:n definierar "bruttomarginal" eller "leverans i tid" kommer den att generera felaktiga frågor. Tekniken är bara så bra som datadefinitionerna under.
Från "Sök" till "Navigering"
Målet med GenBI i ett ERP-sammanhang är att förkorta tiden till insikt. Tänk på skillnaden i det dagliga arbetsflödet:
Standardsättet: Du ser en röd KPI. Du navigerar till menyn. Du öppnar försäljningsordersessionen. Du filtrerar efter datum. Du filtrerar efter status. Du hittar ordern. Slutligen öppnar du den.
GenBI-sättet:
- Fråga: ”Visa mig de 5 kritiska beställningarna som blockerats av kreditprövningen.”
- Visa: Systemet returnerar direkt den exakta listan över order-ID:n.
- Navigera: Du kopierar ID:t (eller klickar på djuplänken) och går direkt till den specifika sessionen för att avblockera den.
Skiftet: Du har inte automatiserat åtgärden (ännu), men du har helt tagit bort den utredningstid som krävs för att hitta det som behöver uppmärksammas.
Titta: Se hur Text-till-SQL-gränssnitt fungerar i praktiken:
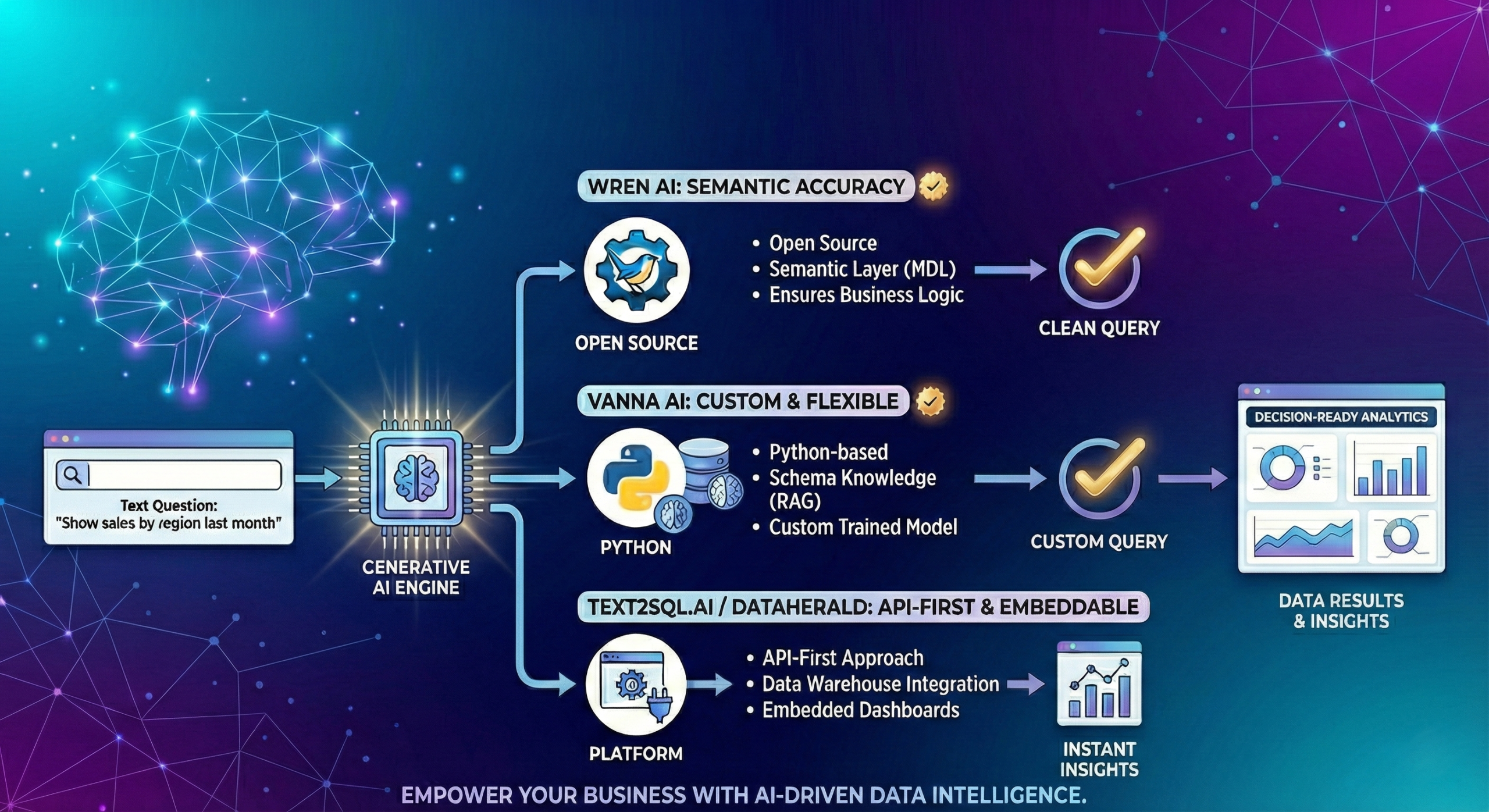
Uppkomsten av text-till-SQL-verktyg
Denna förändring sker inte bara i ett ekosystem. Vi ser en exponentiell ökning av verktyg dedikerade till att lösa problemet med "chatta med databas".
Här är några viktiga aktörer som omformar detta område:
- Wren AI: En semantisk motor med öppen källkod som fokuserar på noggrannhet. Den utmärker sig genom att använda ett "Modeling Definition Language" (MDL) för att skapa det avgörande semantiska lagret vi diskuterade, vilket säkerställer att AI:n förstår affärslogik, inte bara tabellnamn.
- Vanna AI: Ett Python-baserat bibliotek med öppen källkod som låter utvecklare träna en modell specifikt på deras databasschema (med hjälp av RAG). Det är mycket flexibelt för att bygga anpassade interna verktyg.
- Text2SQL.ai / Dataherald: Specialiserade plattformar fokuserar ofta på datalagerkontexter och erbjuder "API-först"-metoder för att bädda in frågor med naturligt språk i befintliga dashboards.
Skillnaden: Medan verktyg som Vanna är bibliotek för utvecklare att bygga anpassade lösningar, syftar plattformar som Wren AI till att vara kompletta GenBI-gränssnitt redo för företagsanvändare. I Infor-världen absorberas dessa funktioner direkt i operativsystemplattformen, men den underliggande logiken förblir densamma.
Verklighetskontrollen
Även om tekniken finns, är det svårare att implementera GenBI i ett komplext tillverknings-ERP än i ett enkelt CRM.
- Komplexitet: Infor LN har tusentals tabeller. AI:n behöver ett massivt kontextuellt minne för att förstå dessa relationer.
- Förtroende: Om AI:n rapporterar "Lagervärdet är 5 miljoner dollar" och finansrapporten Finance "5,2 miljoner dollar", försvinner användarnas förtroende omedelbart.
GenBI är framtidens träningsplats. Innan vi lämnar över nycklarna till Agentic AI (diskuteras i del 3) måste vi lita på att systemet korrekt tolkar data. Om det inte kan svara korrekt på en fråga kan det definitivt inte litas på att det utför en uppgift autonomt.
Nästa steg: Vi analyserar ”Agentvillfarelsen”– och utforskar varför hypen kring helt autonoma agenter ofta kolliderar med den stela verkligheten kring ERP-transaktioner, vilket kräver en seriös ”Människa i loopen”-strategi.
Skriven av Andrea Guaccio
22 december 2025