Hur stela SQL-frågor ger bränsle åt dina AI-hallucinationer
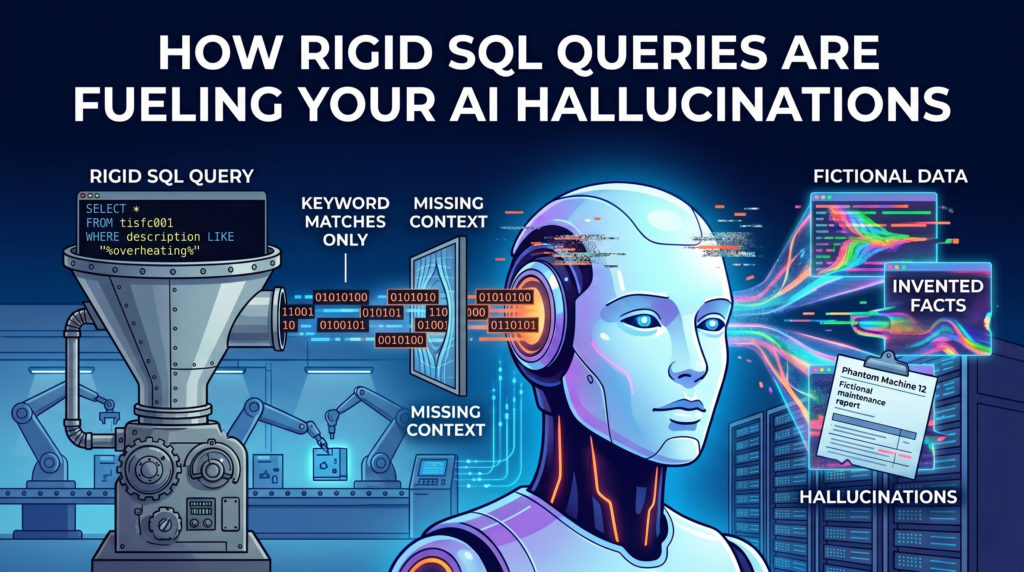
Du kopplar in en glänsande AI i ditt gamla affärssystem och förväntar dig magi. Istället ljuger den dig rakt i ansiktet. Den verkliga boven i dramat? Du ifrågasätter fortfarande historiska dokument som om det vore 2005.
Som ERP-konsult läser jag om dessa scenarier hela tiden. Chefer skyndar sig att installera generativ AI ovanpå affärssystem i hopp om omedelbara, konversationsbaserade insikter. De riktar stora språkmodeller mot gamla datasjöar och väntar på resultaten.
Men den här metoden brukar falla samman i det ögonblick man kliver ut på fabriksgolvet.
Om du försöker extrahera semantisk betydelse med hjälp av rigida, nyckelordsbaserade metoder för att mata en modern AI, ber du praktiskt taget om hallucinationer.
Låt oss analysera hur vi frågar efter företagsdata idag och vart AI-klara arkitekturer faktiskt är på väg. Om du gör fel just nu kommer hela din AI-strategi att spåra ur.
Begränsningen med traditionella ERP-frågor
Databaser i system som Infor LN är fenomenala på vad de faktiskt gör: precision och transaktionell integritet.
De är konstruerade för att exekvera specifika regler snabbt och felfritt. Om du vet exakt vad du letar efter är klassisk SQL perfekt. När du behöver den exakta statusen för en specifik produktionsorder gör ett enkelt SQL-uttryck jobbet. Du riktar in dig på tabellen tisfc001, mappar primärnycklarna och du hämtar din exakta post utan tvetydighet.
Men historisk analys är sällan så kirurgiskt precis.
När en leverantörskedjechef frågar: ”Varför är vi ständigt sena med just den här produktlinjen?”, kan en vanlig SQL-fråga inte ge ett direkt svar. Den kräver att fem olika moduler manuellt kopplas samman för inköp, lagerhållning och produktion. Ännu viktigare är att den kräver att ostrukturerade anteckningar tolkas av olika personer på olika avdelningar.
Tänk dig att undersöka ett återkommande maskinfel och analysera kvalitetsbrister. Du skriver en vanlig SQL-fråga som letar efter WHERE-beskrivningen LIKE '%overheating%'. Din äldre databas kommer lydigt att returnera endast exakta matchningar.
Vad missar den? Allt annat. Den ignorerar helt kritiska poster där en stressad operatör skrev in hög temperatur, hetaeller brinnande komponenter i slutet av sitt skift.
Traditionell SQL saknar semantisk förståelse. Den ser bara stela tecken. När man matar in dessa ofullständiga, nyckelordsfiltrerade resultat i en AI drar modellen slutsatser baserade på en splittrad verklighet. Det är precis här affärsinsikterna dör.
Den semantiska fördelen
Om du behöver undersöka historisk data för att leta efter suddiga korrelationer, ger en vektordatabas en tydlig strukturell fördel.
Datavektorisering översätter mänsklig text till numeriska koordinater som kallas inbäddningar. Detta grupperar data baserat på kontext och faktisk matematisk betydelse. Tänk på en inbäddning som en GPS-koordinat för ett specifikt koncept.
Istället för matchande bokstäver matchar databasen den underliggande betydelsen. Om en planerare skriver försenad av leverantör och en lageroperatör loggar väntande artiklar, ser en klassisk SQL-fråga två orelaterade problem. En vektoriserad databas identifierar att det är exakt samma problem.
I en vektoriserad databas placeras termerna överhettning och hög temperatur matematiskt bredvid varandra.
Genom att flytta dina transaktionsdata till en vektoraktiverad databas som Google AlloyDBslutar du matcha strängar och börjar matcha betydelse. Detta utnyttjar vanligtvis strömningspipelines för att flytta data säkert bort från ERP-kärnan.
Du får möjlighet att söka efter åratal av historisk data med hjälp av naturligt språk. Systemet förstår avsikten. Användare behöver inte längre memorera komplexa SQL-syntaxer, navigera i obskyra tabeller eller gissa äldre förkortningar.
Rätt arkitektur att börja med: RAG och kärnisolering
Du kanske frestas att tillämpa generativ AI direkt på ditt transaktionella ERP-system. Gör det inte. Att göra det kommer att försämra den operativa prestandan avsevärt och riskera att låsa ditt kärnsystem.
LLM-system är otroligt tunga. Om du riktar en konversationsbaserad AI direkt mot dina transaktionstabeller i realtid kommer du att förlama din dagliga verksamhet. Lagerarbetaren som försöker skicka en lastbil med varor ska inte behöva vänta på systemet för att en chef ber AI:n att analysera tio års underhållsdata.
Den moderna lösningen bygger på Retrieval-Augmented Generation (RAG) och kärnisolering. Ett utmärkt exempel är Infors övergång från deras äldre Coleman ML. De använder för närvarande LangChain för att bygga agenter som kan utföra djupt semantiskt resonemang, säkert förankrade i affärslogik.
RAG-arbetsflödet följer vanligtvis dessa operativa steg:
- Avlastning: Du strömmar ERP-data bort från transaktionskärnan. Med hjälp av verktyg som Infor Data Fabric skickar du dessa data till din vektordatabas. Detta håller ditt huvudsystem igång smidigt.
- Hämtning: En användare ställer en fråga på naturligt språk. AlloyDB-vektordatabasen utför en höghastighetssökning för att hitta konceptuellt relevanta historiska poster.
- Extraktion: Endast dessa giltiga poster skickas som en sanningskontext till en extern stor språkmodell som Vertex AI. LLM:n bearbetar detta och genererar ett exakt svar utan att någonsin vidröra det aktuella ERP-systemet.
Detta RAG-arbetsflöde är den rätta grunden för alla AI-initiativ för företag just nu. Men betrakta det som en utgångspunkt, inte en destination.
Branschen rör sig redan mot Agentic Search: arkitekturer där AI inte utför en enda, statisk semantisk sökning utan istället autonomt bestämmer hur och var den ska söka. Den cyklar genom flera hämtningsstrategier (vektorsökning, strukturerade frågor, filsystem, kunskapsgrafer) baserat på frågans komplexitet.
Andrej Karpathy uppmärksammade nyligen ett relaterat mönster: LLM Wiki. En AI-agent förkompilerar rå källdata till en strukturerad, sammanlänkad kunskapsbas. Istället för att hämta textbitar varje gång, frågar agenten efter en ren, organiserad artefakt som den redan har byggt upp, vilket kompletterar intelligensen över tid.
För de flesta ERP-miljöer idag är en välbyggd RAG-pipeline rätt drag. Men begränsningarna för kontextfönster som gjorde vektor chunking obligatorisk krymper snabbt. Om du designar din arkitektur utan någon exit ramp mot agentiska mönster kommer du att uppdatera den igen om arton månader.
Att döda hallucinationerna
En AI-hallucination uppstår när en LLM genererar utdata som är flytande, övertygande, men faktamässigt absurd. Dessa modeller "känner inte till" fakta; de förutsäger bara sannolikheter baserat på deras underliggande arkitektur.
I komplexa industriella miljöer är en hallucination ett kritiskt fel. AI:n kan med säkerhet uppfinna ett underhållsschema som passar ett statistiskt mönster men som inte existerar i verkligheten. Den kan föreslå att man beställer delar som utgått för ett decennium sedan helt enkelt för att de ofta förekom i gamla loggar.
Vi kan inte matematiskt eliminera hallucinationer, men vi måste minska dem tills de är statistiskt irrelevanta. Här är strikta regler som du måste tillämpa:
- Kräv strikt grundning: Tvinga LLM:en att uteslutande förlita sig på RAG-kontexten som tillhandahålls av din vektordatabas. Blockera explicit dess förtränade internetkunskap för att genomdriva strikt företagsgrundning.
- Implementera nolltemperatur: Ställ in modellens temperatur på noll. Ta bort kreativiteten från AI:n för att säkerställa deterministiska, mycket repeterbara resultat. Vi vill ha kirurgisk precision, inte kreativt skrivande.
- Bygg en obligatorisk reservlösning: Tvinga LLM:en att ange Data hittades inte om svaret förlitar sig på data utanför det hämtade sammanhanget genom rigorös prompt engineering.
- Prioritera datakvalitet: Ingen av dessa avancerade arkitekturer spelar någon roll om dina källdata är skräp. ERP-datan som flödar in i vektordatabasen måste vara ren och normaliserad.
Användbara insikter för IT-chefer
Sluta jaga hypen. Att bara köpa en AI-licens åtgärdar inte en trasig företagsarkitektur. Om ditt ERP-system är en röra av ostrukturerade lösningar idag, kommer det bara att automatisera förvirringen att mata en AI med det.
Kombinera den transaktionella precisionen i ditt ERP-system med den semantiska förståelsen hos en vektordatabas, så stoppar du äntligen AI:n från att gissna.
Börja med att bedöma din nuvarande datamognad innan du köper några AI-verktyg. Utvärdera hur dina användare för närvarande loggar problem och om dessa beskrivningar är tillräckligt standardiserade för att kunna vektoriseras effektivt.
Utvärdera sedan vektordatabaser för historisk analys. Kartlägg dina frågeintentioner och framför allt, skydda ditt kärnsystem genom att bygga en frikopplad RAG-arkitektur. Slutligen, designa med en utgångsramp. Bygg ditt hämtningslager som en modulär komponent, inte en monolit. När agentiska mönster mognar för företagsanvändning bör du kunna byta eller utöka din hämtningsstrategi utan att bygga om allt från grunden.
Om ert ERP-system fortfarande kämpar med att tillhandahålla grundläggande, tydlig data idag, kommer en semantisk AI bara att göra att det misslyckas snabbare.
Om din databas är trasig kommer AI bara att automatisera din förvirring i stor skala. Åtgärda arkitekturen innan du köper licensen.
Skriven av Andrea Guaccio
5 maj 2026