AI-dödaren: Varför smutsig data kommer att ruinera din agent

(Del 4 i serien: ”ERP-intelligensutvecklingen: Från data till agenter”)
I del 1definierade vi termerna.
I del 2undersökte vi data.
I del 3utforskade vi farorna med autonoma agenter.
Nu måste vi möta den brutala verkligheten som dödar upp till 85 % av AI-projekt innan de ens har börjat.
Det är inte algoritmen. Det är inte GPU-kraften. Det är dina masterdata.
Vi vill alla ha det självkörande företaget, men fråga dig själv: skulle du aktivera autopiloten i en bil om sensorerna var täckta av lera och GPS-kartan var från 1990?
Det är precis vad vi gör när vi släpper lös GenAI på en äldre ERP-databas full av dubbletter, saknade ledtider och ANVÄND INTE -beskrivningar.
Multiplikatoreffekten "Garbage In"
I den traditionella ERP-världen "skräp in, skräp ut" ett irritationsmoment.
- Scenario: ledtiden i systemet har 0 dagar, men den verkliga ledtiden är 30 dagar.
- Gammalt resultat: MRP föreslår att beställningen görs för sent.
Planeraren tittar på det, skrattar, ignorerar systemet och beställer det manuellt baserat på stamkunskap. - Skyddsnätet: Människan var felkorrigeringslagret.
I AI-världen är det skyddsnätet borta. Som McKinsey påpekar i sin analys av AI i leveranskedjor, producerar statistiska modeller "otillförlitliga resultat" när data har brister, vilket potentiellt kan kosta organisationer 8–12 % i förlorade intäkter.
- Scenario: ledtiden är tom.
- Nytt resultat: Leveranskedjans agent ser 0 dagar.
Den väntar till sista minuten. Den misslyckas med att säkra material. Den stänger ner produktionslinjen. Eller ännu värre, den hallucinerar en ledtid baserad på ett generiskt branschgenomsnitt som inte gäller för din specifika nischlegering.
Regel nummer 1 för ERP AI: Artificiell intelligens antar att dina data är sanna.
Den saknar sunt förnuft för att veta att "Artikel A" och "Artikel A-GAMMEL" är samma sak.
Kunskapsklyftan inom stammen
Den största utmaningen för AI inom ERP är att den verkliga verksamhetsmodellen ofta finns i människors huvuden, inte i databastabellerna.
- Explicita data: vad finns i Infor LN / M3 (inköpsorderdatum, antal).
- Implicita data: Leverantör X säger 2 veckor, men de tar alltid 4 eller skickar aldrig känslig elektronik på fredag.
En LLM (Large Language Model) kan inte läsa tankar.
Om du vill att en agent ska hantera upphandling måste du konvertera implicit kunskap till explicit data.
Det betyder att fält som tidigare var "bra att ha" (som leverantörsprestandabetyg, exakta ledtider, säkerhetslagerlogik) nu är obligatoriska.
Vektorisering: plåstret för ostrukturerad data
Det finns en ljusglimt. Traditionella affärssystem hade svårt med ostrukturerad data (PDF-specifikationer, e-postkedjor, kommentarsfält).
Generativ AI älskar ostrukturerad data.
Genom en process som kallas vektorisering (inbäddning) kan vi mata in PDF-manualer och tekniska specifikationer i en vektordatabas.
Detta gör det möjligt för en agent att svara: "Har vi en motor som är kompatibel med dessa spänningsspecifikationer?" genom att läsa de bifogade PDF-filerna.
Detta skapar dock en ny styrningsmardröm: Om du har föråldrade PDF-filer bifogade till din artikelmapp kommer AI:n med säkerhet att rekommendera föråldrade delar. Att dina dokument är nu lika viktigt som att dina rader och kolumner.
Färdplanen för AI-beredskap: Städa upp eller ge upp
Innan du köper en AI-licens behöver du en datastrategi. Enligt MIT Sloan Management Reviewendast 24 % av företagen sig för närvarande som "datadrivna", vilket belyser det enorma gapet mellan ambition och verklighet.
- för att avduplicera masterdata
kan inte optimera lagret om samma lager finns som tre olika artikelkoder.
För att åtgärda detta måste du aggressivt konsolidera artikelmall- och affärspartnerposter för att säkerställa att AI:n ser en "enda version av sanningen". - Berika metadata
AI behöver kontext för att fungera effektivt.
En kod som "Item 10202" betyder ingenting för en juridiklärare utan omfattande deskriptorer.
För att möjliggöra intelligens måste du se till att beskrivningarna är standardiserade, attributen är fullständigt ifyllda och tekniska klassificeringar tillämpas strikt över hela linjen. - Sluta skriva ner beroendet av "fri text".
Sluta skriva viktiga instruktioner i textanteckningar eller ostrukturerade kommentarer.
Affärslogik måste flyttas till strukturerade fält där ERP-logiken och agenten kan verifiera och agera utifrån den på ett tillförlitligt sätt, snarare än att gissa avsikten bakom en handskriven anteckning.
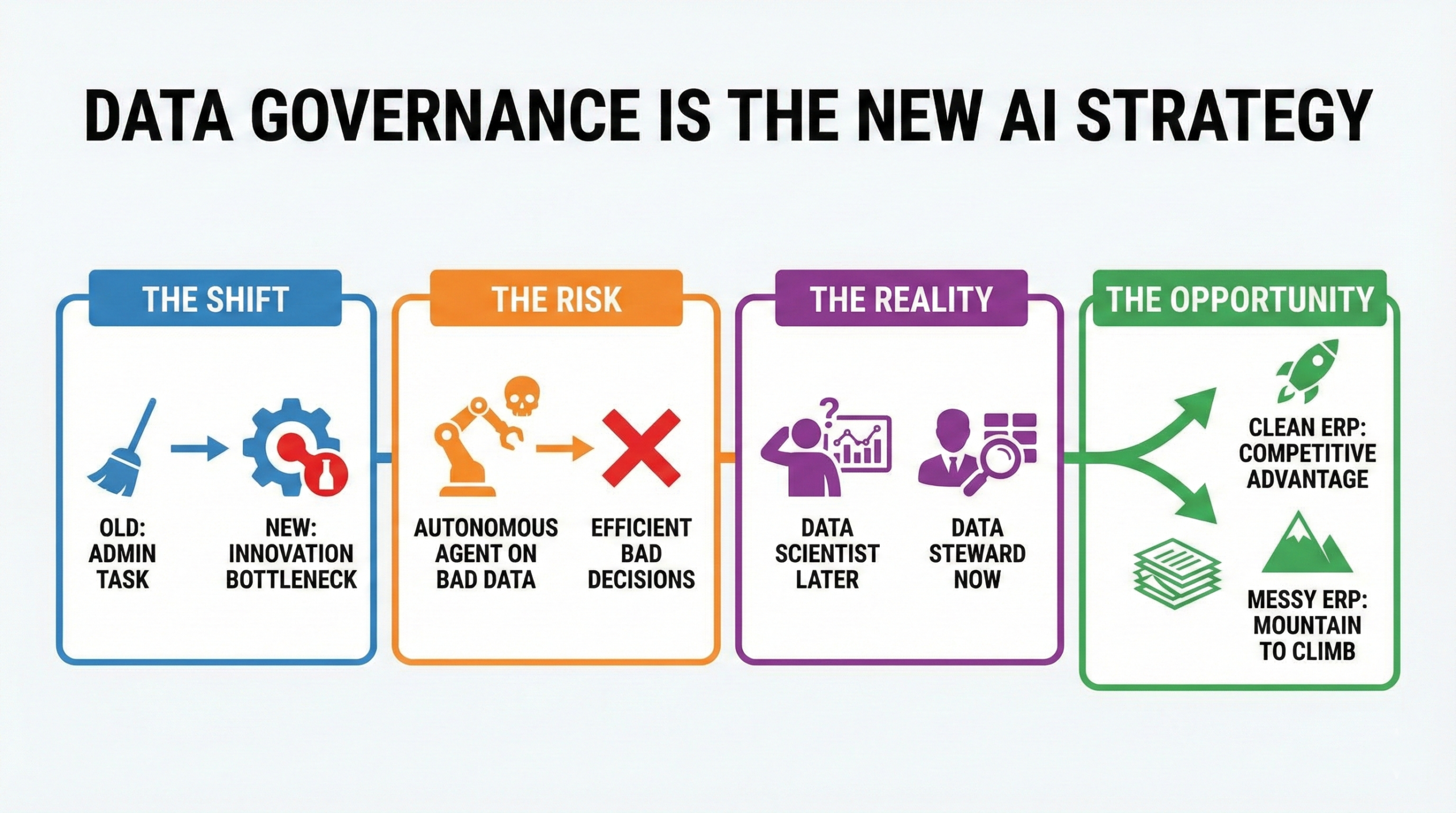
Utvecklingen från data till intelligens till agenter är oundviklig. Verktygen finns här och visionen är tydlig. Men bränslet för denna motor är trovärdighet. Och trovärdighet kommer från ett ställe: noggrannheten i dokumentationen.
Börja städa.
Viktiga källor och vidare läsning
- Gartner: Varför 85 % av AI-projekt misslyckas – Förutsäger höga misslyckandefrekvenser på grund av felaktiga data, partiskhet eller hanteringsproblem.
- Harvard Business Review: Databeredskap för AI-revolutionen – 91 % av ledarna säger att en pålitlig databas är avgörande, men endast 55 % litar på sina nuvarande data.
- MIT Sloan: Att få ut det mesta av AI – Identifierar kultur och datakunskap som de främsta hindren för AI-framgång.
Nästa steg: Vi har tekniken, och vi har (förhoppningsvis) rena data. Men vad händer med människor? I den sista delen av den här serien utforskar vi den mänskliga evolutionen: varför ERP-experter kommer att sluta med datainmatning och börja med algoritmgranskning.
Skriven av Andrea Guaccio
7 januari 2026