Zabójca sztucznej inteligencji: dlaczego brudne dane doprowadzą Twojego agenta do bankructwa

(Część 4 serii: „Ewolucja inteligencji ERP: od danych do agentów”)
W Części 1zdefiniowaliśmy te terminy.
W Części 2przeanalizowaliśmy dane.
W Części 3zbadaliśmy zagrożenia związane z autonomicznymi agentami.
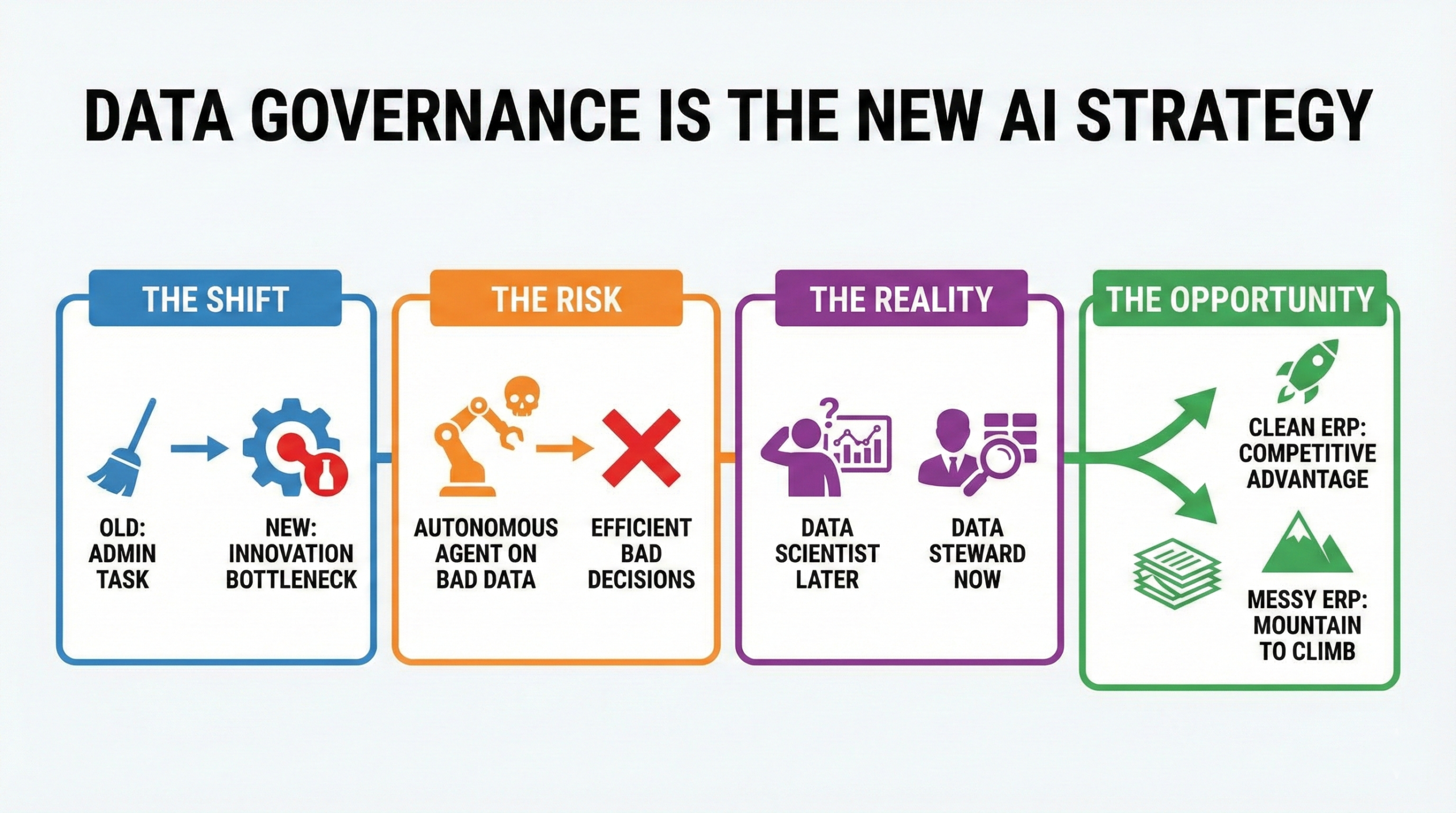
Teraz musimy zmierzyć się z brutalną rzeczywistością, która niweczy aż 85% projektów AI jeszcze przed ich rozpoczęciem.
To nie algorytm. To nie moc GPU. To Twoje dane podstawowe.
Wszyscy pragniemy autonomicznego przedsiębiorstwa, ale zadajmy sobie pytanie: czy włączylibyście autopilota w samochodzie, gdyby czujniki były pokryte błotem, a mapa GPS pochodziła z 1990 roku?
Właśnie to robimy, publikując GenAI w przestarzałej bazie danych ERP pełnej duplikatów, brakujących terminów realizacji i NIEUŻYWANYCH opisów.
Efekt mnożnikowy „śmieci na wejściu”
W tradycyjnym świecie ERP zasada „śmieci na wejściu, śmieci na wyjściu” była uciążliwa.
- Scenariusz: czas realizacji zamówienia w systemie wynosi 0 dni, ale rzeczywisty czas realizacji wynosi 30 dni.
- Poprzedni wynik: MRP sugeruje zamówienie za późno.
Planista patrzy na to, śmieje się, ignoruje system i zamawia ręcznie, opierając się na wiedzy plemiennej. - Sieć bezpieczeństwa: Człowiek stanowił warstwę korekcji błędów.
W świecie sztucznej inteligencji ta siatka bezpieczeństwa zniknęła. Jak zauważa McKinsey w swojej analizie sztucznej inteligencji w łańcuchach dostaw, modele statystyczne generują „niewiarygodne wyniki”, gdy dane zawierają błędy, co może kosztować organizacje 8-12% utraconych przychodów
- Scenariusz: czas realizacji jest pusty.
- Nowy wynik: agent łańcucha dostaw widzi 0 dni.
Czeka do ostatniej chwili. Nie zabezpiecza materiałów. Zamyka linię produkcyjną. Albo, co gorsza, wylicza czas realizacji na podstawie ogólnej średniej branżowej, która nie ma zastosowania do konkretnego, niszowego stopu.
Zasada nr 1 sztucznej inteligencji w systemach ERP: Sztuczna inteligencja zakłada, że Twoje dane są prawdziwe.
Brakuje jej zdrowego rozsądku, by wiedzieć, że „Pozycja A” i „Pozycja A-OLD” to to samo.
Luka w wiedzy plemiennej
Największym wyzwaniem dla sztucznej inteligencji w systemach ERP jest to, że prawdziwy model operacyjny często mieści się w głowach ludzi, a nie w tabelach bazy danych.
- Dane jawne: co zawiera Infor LN / M3 (daty zamówień, ilość).
- Dane ukryte: Dostawca X twierdzi, że zajmie to 2 tygodnie, ale zawsze zajmuje to 4 tygodnie lub nigdy nie wysyła delikatnych urządzeń elektronicznych w piątki.
LLM (Large Language Model) nie potrafi czytać w myślach. Aby agent mógł zarządzać zamówieniami, musisz przekształcić wiedzę ukrytą w dane jawne . Oznacza to , że pola, które wcześniej były „miłym dodatkiem” (takie jak oceny wydajności dostawców, precyzyjne terminy realizacji zamówień, logika zapasów bezpieczeństwa), są teraz obowiązkowe .
Wektoryzacja: plaster na nieustrukturyzowane dane
Jest jednak i pozytywna strona tej sytuacji. Tradycyjne systemy ERP miały problemy z nieustrukturyzowanymi danymi (specyfikacje PDF, łańcuchy e-maili, pola komentarzy).
Generatywna sztuczna inteligencja uwielbia nieustrukturyzowane dane.
Poprzez proces zwany wektoryzacją (osadzaniem) możemy wprowadzić instrukcje PDF i specyfikacje techniczne do bazy danych wektorów.
Dzięki temu agent może odpowiedzieć na pytanie: „Czy mamy silnik zgodny z tymi parametrami napięcia?” , odczytując załączone pliki PDF.
Stwarza to jednak nowy koszmar w zarządzaniu: jeśli do głównego elementu masz dołączone nieaktualne pliki PDF, sztuczna inteligencja z pewnością zarekomenduje nieaktualne części. Czystość dokumentów jest teraz równie ważna, jak czystość wierszy i kolumn.
Plan działania na rzecz gotowości na sztuczną inteligencję: posprzątać lub się poddać
Zanim kupisz licencję na sztuczną inteligencję, potrzebujesz strategii danych. Według MIT Sloan Management Review, tylko 24% firm określa się obecnie jako „oparte na danych”, co uwydatnia ogromną przepaść między ambicjami a rzeczywistością.
- danych głównych deduplikujących
nie mogą optymalizować zapasów, jeśli ten sam element występuje w trzech różnych kodach pozycji.
Aby to naprawić, należy agresywnie skonsolidować rekordy danych głównych pozycji i partnerów biznesowych, aby zapewnić sztucznej inteligencji dostęp do „jednej wersji prawdy”. - Wzbogać metadane. Sztuczna
inteligencja potrzebuje kontekstu, aby działać efektywnie.
Kod taki jak „Pozycja 10202” nic nie znaczy dla LLM bez bogatych deskryptorów.
Aby umożliwić inteligencję, należy zadbać o standaryzację opisów, pełne wypełnienie atrybutów i ścisłe stosowanie klasyfikacji technicznych. - Pokonaj uzależnienie od „swobodnego tekstu”.
Przestań umieszczać kluczowe instrukcje w notatkach tekstowych lub niestrukturyzowanych komentarzach.
Logika biznesowa musi zostać przeniesiona do ustrukturyzowanych pól, gdzie logika ERP i agent mogą ją niezawodnie weryfikować i działać na jej podstawie, zamiast zgadywać intencje stojące za odręczną notatką.
Ewolucja od danych do inteligencji i agentów jest nieunikniona. Narzędzia są dostępne, a wizja jest jasna. Ale paliwem napędzającym ten silnik jest wiarygodność. A wiarygodność pochodzi z jednego źródła: dokładności danych.
Rozpocznij sprzątanie.
Kluczowe źródła i dalsza lektura
- Gartner: Dlaczego 85% projektów AI kończy się niepowodzeniem – prognozuje wysoki wskaźnik niepowodzeń z powodu błędnych danych, stronniczości lub problemów z zarządzaniem.
- Harvard Business Review: Gotowość danych na rewolucję sztucznej inteligencji – 91% liderów twierdzi, że niezawodna baza danych jest niezbędna, ale tylko 55% ufa swoim obecnym danym.
- MIT Sloan: Jak najlepiej wykorzystać sztuczną inteligencję – Wskazuje kulturę i znajomość danych jako główne przeszkody na drodze do sukcesu sztucznej inteligencji.
Dalej: mamy technologię i (miejmy nadzieję) czyste dane. Ale co się dzieje z ludźmi? W ostatniej części tej serii zgłębiamy ewolucję człowieka: dlaczego ekspert ERP jutra przestanie zajmować się wprowadzaniem danych i zacznie zajmować się audytem algorytmów.
Napisane przez Andreę Guaccio
7 stycznia 2026 r