Wie starre SQL-Abfragen Ihre KI-Halluzinationen befeuern
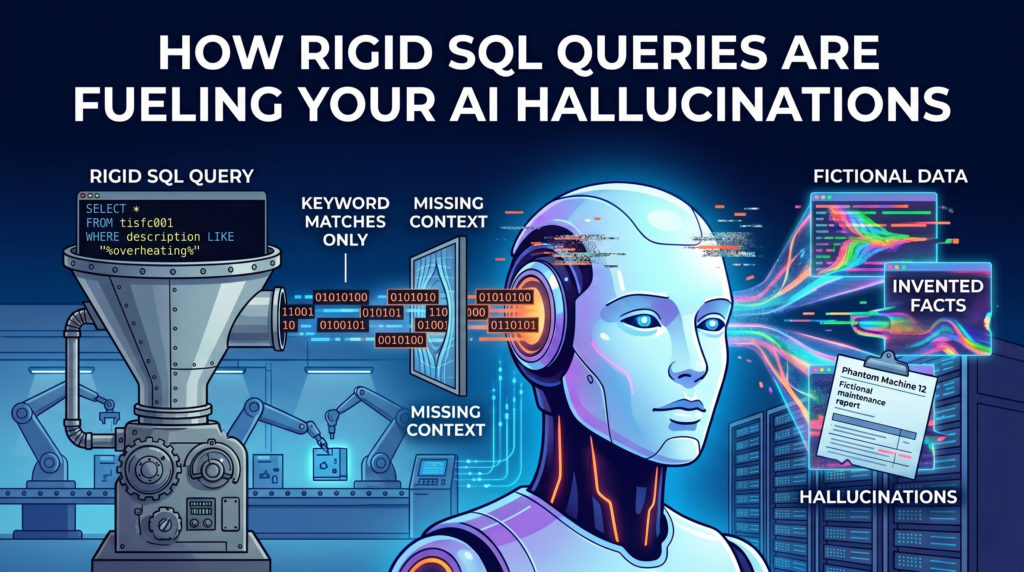
Sie integrieren eine moderne KI in Ihr veraltetes ERP-System und erwarten Wunder. Stattdessen lügt sie Ihnen dreist ins Gesicht. Der wahre Grund? Sie greifen immer noch auf historische Datensätze zu, als wäre es 2005.
Als ERP-Berater lese ich ständig von solchen Szenarien. Führungskräfte setzen generative KI übereilt in ihren Unternehmenssystemen ein und hoffen auf sofortige, dialogbasierte Erkenntnisse. Sie wenden große Sprachmodelle auf veraltete Datenbestände an und warten auf die Ergebnisse.
Doch dieser Ansatz scheitert in der Regel, sobald man die Fabrikhalle betritt.
Wer versucht, mithilfe starrer, schlüsselwortbasierter Methoden semantische Bedeutung zu extrahieren, um eine moderne KI zu füttern, provoziert geradezu Halluzinationen.
Lassen Sie uns analysieren, wie wir heute Unternehmensdaten abfragen und wohin sich KI-fähige Architekturen tatsächlich entwickeln. Wenn Sie hier jetzt Fehler machen, wird Ihre gesamte KI-Strategie scheitern.
Die Grenzen traditioneller ERP-Abfragen
Datenbanken in Systemen wie Infor LN sind in dem, was sie eigentlich leisten, phänomenal: Präzision und Transaktionsintegrität.
Sie sind darauf ausgelegt, spezifische Regeln schnell und fehlerfrei auszuführen. Wenn Sie genau wissen, wonach Sie suchen, ist klassisches SQL ideal. Benötigen Sie den genauen Status eines bestimmten Produktionsauftrags, genügt eine einfache SQL-Anweisung. Sie wählen die Tabelle tisfc001 aus, ordnen die Primärschlüssel zu und erhalten Ihren Datensatz eindeutig.
Doch historische Analysen sind selten so präzise wie ein Chirurg.
Wenn ein Supply-Chain-Manager fragt: „Warum sind wir bei dieser Produktlinie ständig im Verzug?“, kann eine Standard-SQL-Abfrage diese Frage nicht direkt beantworten. Sie erfordert die manuelle Verknüpfung von fünf verschiedenen Modulen aus Einkauf, Lagerhaltung und Produktion. Noch wichtiger ist jedoch die Interpretation unstrukturierter Notizen verschiedener Mitarbeiter aus unterschiedlichen Abteilungen.
Stellen Sie sich vor, Sie untersuchen einen wiederkehrenden Maschinenausfall und analysieren Qualitätsmängel. Sie schreiben eine Standard-SQL-Abfrage, die nach Einträgen mit der Beschreibung LIKE '%overheating%' sucht. Ihre bestehende Datenbank gibt jedoch nur exakte Übereinstimmungen zurück.
Was fehlt? Alles andere. Es ignoriert völlig wichtige Datensätze, in denen ein in Eile arbeitender Bediener am Ende seiner Schicht „hohe Temperatur“ , „heißlaufende“ oder „durchbrennende Bauteile“ eingegeben hat
Traditionelles SQL besitzt kein semantisches Verständnis. Es interpretiert lediglich starre Zeichen. Werden diese unvollständigen, nach Schlüsselwörtern gefilterten Ergebnisse in eine KI eingespeist, zieht das Modell Schlüsse aus einer fragmentierten Realität. Genau hier gehen wertvolle Geschäftseinblicke verloren.
Der semantische Vorteil
Wenn Sie historische Daten nach unklaren Korrelationen durchsuchen müssen, bietet eine Vektordatenbank einen klaren strukturellen Vorteil.
Die Datenvektorisierung übersetzt menschlichen Text in numerische Koordinaten, sogenannte Embeddings. Dadurch werden Daten anhand ihres Kontexts und ihrer mathematischen Bedeutung gruppiert. Man kann sich ein Embedding wie eine GPS-Koordinate für ein bestimmtes Konzept vorstellen.
Anstatt Buchstaben abzugleichen, gleicht die Datenbank die zugrundeliegende Bedeutung ab. Wenn ein Planer „ Verzögerung durch Zulieferer“ und ein Lagermitarbeiter „ Warten auf Teile“, erkennt eine klassische SQL-Abfrage zwei unabhängige Probleme. Eine vektorisierte Datenbank erkennt jedoch, dass es sich um ein und dasselbe Problem handelt.
In einer vektorisierten Datenbank werden die Begriffe Überhitzung und hohe Temperatur mathematisch direkt nebeneinander platziert.
Durch die Auslagerung Ihrer Transaktionsdaten in eine vektorbasierte Datenbank wie Google AlloyDBwerden nicht mehr Zeichenketten, sondern deren Bedeutung abgeglichen. Dies geschieht üblicherweise mithilfe von Stream-Pipelines, um die Daten sicher vom ERP-Kern zu trennen.
Sie erhalten die Möglichkeit, jahrelange historische Daten in natürlicher Sprache abzufragen. Das System versteht die Absicht. Benutzer müssen sich keine komplexen SQL-Syntaxen mehr merken, unübersichtliche Tabellen durchsuchen oder veraltete Abkürzungen erraten.
Die richtige Architektur für den Anfang: RAG & Kernisolierung
Sie könnten in Versuchung geraten, generative KI direkt in Ihr transaktionales ERP-System zu integrieren. Tun Sie das nicht. Dies wird die operative Leistungsfähigkeit erheblich beeinträchtigen und das Risiko bergen, Ihr Kernsystem lahmzulegen.
LLMs sind extrem ressourcenintensiv. Wenn Sie eine dialogbasierte KI direkt auf Ihre Live-Transaktionstabellen anwenden, werden Sie Ihren täglichen Betrieb lahmlegen. Der Lagermitarbeiter, der eine LKW-Ladung Waren versenden will, sollte nicht auf das System warten müssen, nur weil ein Manager die KI bittet, zehn Jahre an Wartungsdaten zu analysieren.
Die moderne Lösung basiert auf Retrieval-Augmented Generation (RAG) und Kernisolation. Ein Paradebeispiel ist der Übergang von Infor von ihrem alten Coleman ML-System. Aktuell nutzen sie LangChain, um Agenten zu entwickeln, die tiefgreifendes semantisches Schließen ermöglichen und dabei sicher in der Geschäftslogik verankert sind.
Der RAG-Workflow folgt typischerweise diesen Arbeitsschritten:
- Auslagerung: Sie lagern ERP-Daten vom Transaktionskern aus. Mithilfe von Tools wie Infor Data Fabric übertragen Sie diese Daten in Ihre Vektordatenbank. Dadurch läuft Ihr Hauptsystem reibungslos weiter.
- Abfrage: Ein Benutzer stellt eine Frage in natürlicher Sprache. Die AlloyDB-Vektordatenbank führt eine Hochgeschwindigkeitssuche durch, um konzeptionell relevante historische Datensätze zu finden.
- Extraktion: Nur diese gültigen Datensätze werden als Kontext der Wahrheit an ein externes großes Sprachmodell wie Vertex AI gesendet. Das Sprachmodell verarbeitet diese Daten und generiert eine präzise Antwort, ohne jemals auf das Live-ERP-System zuzugreifen.
Dieser RAG-Workflow bildet aktuell die richtige Grundlage für jede KI-Initiative in Unternehmen. Betrachten Sie ihn jedoch als Ausgangspunkt, nicht als Ziel.
Die Branche bewegt sich bereits in Richtung agentenbasierter Suche: Architekturen, in denen KI keine statische semantische Suche durchführt, sondern autonom entscheidet, wie und wo gesucht wird. Sie durchläuft je nach Komplexität der Frage verschiedene Suchstrategien (Vektorsuche, strukturierte Anfragen, Dateisysteme, Wissensgraphen).
Andrej Karpathy lenkte kürzlich die Aufmerksamkeit auf ein verwandtes Muster: das LLM-Wiki. Ein KI-Agent kompiliert Rohdaten vorab zu einer strukturierten, vernetzten Wissensbasis. Anstatt jedes Mal Textfragmente abzurufen, greift der Agent auf ein bereits erstelltes, übersichtliches Artefakt zurück und erweitert so seine Intelligenz im Laufe der Zeit.
Für die meisten ERP-Umgebungen ist heutzutage eine gut strukturierte RAG-Pipeline der richtige Ansatz. Die Kontextfensterbeschränkungen, die das Vektor-Chunking bisher erforderlich machten, schrumpfen jedoch rapide. Wenn Sie Ihre Architektur ohne Ausstiegsmöglichkeit hin zu agentenbasierten Mustern entwerfen, müssen Sie sie in achtzehn Monaten erneut aktualisieren.
Die Halluzinationen töten
Eine KI-Halluzination tritt auf, wenn ein LLM Ausgaben generiert, die zwar flüssig und überzeugend, aber faktisch absurd sind. Diese Modelle „kennen“ keine Fakten; sie prognostizieren lediglich Wahrscheinlichkeiten auf Grundlage ihrer zugrundeliegenden Architektur.
In komplexen Industrieumgebungen ist eine Fehlfunktion ein schwerwiegender Fehler. Die KI könnte beispielsweise selbstbewusst einen Wartungsplan erstellen, der zwar einem statistischen Muster entspricht, aber in der Realität nicht existiert. Sie könnte vorschlagen, Teile zu bestellen, die bereits vor zehn Jahren aus dem Sortiment genommen wurden, nur weil sie häufig in alten Protokollen auftauchten.
Halluzinationen lassen sich mathematisch nicht vollständig eliminieren, aber wir müssen sie so weit reduzieren, dass sie statistisch irrelevant sind. Hier sind strenge Regeln, die Sie unbedingt einhalten müssen:
- Strenge Datenbasis erzwingen: Zwingen Sie das LLM, sich ausschließlich auf den von Ihrer Vektordatenbank bereitgestellten RAG-Kontext zu stützen . Blockieren Sie explizit dessen vorab trainiertes Internetwissen, um eine strikte unternehmensweite Datenbasis zu gewährleisten .
- Implementierung der Nulltemperatur: Setzen Sie die Modelltemperatur auf Null. Um deterministische und hochgradig reproduzierbare Ergebnisse zu gewährleisten, wird die Kreativität der KI eingeschränkt. Wir benötigen chirurgische Präzision, keine kreative Erzählkunst.
- Erstellen Sie einen obligatorischen Fallback: Erzwingen Sie durch rigoroses Prompt-Engineering, dass das LLM „ Daten nicht gefunden“ meldet, wenn die Antwort auf Daten außerhalb des abgerufenen Kontexts beruht.
- Datenqualität hat oberste Priorität: Selbst die ausgefeilte Architektur ist nutzlos, wenn die Quelldaten fehlerhaft sind. Die ERP-Daten, die in die Vektordatenbank fließen, müssen sauber und normalisiert sein.
Praktische Erkenntnisse für IT-Führungskräfte
Hören Sie auf, dem Hype hinterherzujagen. Der bloße Kauf einer KI-Lizenz behebt keine fehlerhafte Unternehmensarchitektur. Wenn Ihr ERP-System heute aus einem unstrukturierten Flickwerk besteht, wird die Nutzung einer KI das Chaos nur noch verschlimmern.
Kombinieren Sie die transaktionale Präzision Ihres ERP-Systems mit dem semantischen Verständnis einer Vektordatenbank, und Sie verhindern endgültig, dass die KI rät.
Bevor Sie KI-Tools erwerben, sollten Sie zunächst den Reifegrad Ihrer aktuellen Daten analysieren. Prüfen Sie, wie Ihre Nutzer derzeit Probleme protokollieren und ob diese Beschreibungen ausreichend standardisiert sind, um eine effektive Vektorisierung zu ermöglichen.
Als Nächstes sollten Sie Vektordatenbanken für die historische Analyse evaluieren. Bilden Sie Ihre Abfrageabsichten ab und schützen Sie vor allem Ihr Kernsystem durch den Aufbau einer entkoppelten RAG-Architektur. Planen Sie abschließend einen Ausstieg ein. Entwickeln Sie Ihre Abrufschicht als modulare Komponente, nicht als monolithischen Baustein. Sobald agentenbasierte Muster für den Unternehmenseinsatz ausgereift sind, sollten Sie Ihre Abrufstrategie austauschen oder erweitern können, ohne alles von Grund auf neu entwickeln zu müssen.
Wenn Ihr ERP-System heute schon Schwierigkeiten hat, grundlegende, saubere Daten zu liefern, wird das Hinzufügen einer semantischen KI das Scheitern nur noch beschleunigen.
Wenn Ihre Datengrundlage mangelhaft ist, wird KI Ihre Verwirrung nur im großen Stil automatisieren. Korrigieren Sie die Architektur, bevor Sie die Lizenz erwerben.
Verfasst von Andrea Guaccio
5. Mai 2026