Der KI-Killer: Warum fehlerhafte Daten Ihren Agenten ruinieren werden

(Teil 4 der Serie: „Die ERP-Intelligenz-Evolution: Von Daten zu Agenten“)
In Teil 1haben wir die Begriffe definiert.
In Teil 2haben wir die Daten abgefragt.
In Teil 3haben wir die Gefahren autonomer Agenten untersucht.
Nun müssen wir uns der brutalen Realität stellen, die bis zu 85 % aller KI-Projekte , bevor sie überhaupt beginnen.
Es liegt nicht am Algorithmus. Es liegt nicht an der GPU-Leistung. Es liegt an Ihren Stammdaten.
Wir alle wünschen uns das autonome Fahren, aber fragen Sie sich selbst: Würden Sie den Autopiloten in einem Auto aktivieren, wenn die Sensoren mit Schlamm bedeckt wären und die GPS-Karte aus dem Jahr 1990 stammte?
Genau das tun wir, wenn wir GenAI auf eine veraltete ERP-Datenbank voller Duplikate, fehlender Lieferzeiten und NICHT VERWENDET werden, anwenden .
Der „Müll rein“-Multiplikatoreffekt
In der traditionellen ERP-Welt „Müll rein, Müll raus“ ein Ärgernis.
- Szenario: Die Lieferzeit im System beträgt 0 Tage, die tatsächliche Lieferzeit beträgt jedoch 30 Tage.
- Altes Ergebnis: Das MRP-System schlägt eine zu späte Bestellung vor.
Der Planer sieht sich das an, lacht, ignoriert das System und bestellt manuell auf Basis seiner Erfahrung. - Das Sicherheitsnetz: Der Mensch war die Fehlerkorrekturschicht.
In der Welt der KI ist dieses Sicherheitsnetz verschwunden. Wie McKinsey in seiner Analyse von KI in Lieferketten aufzeigt, liefern statistische Modelle bei fehlerhaften Daten „unzuverlässige Ergebnisse“, was Unternehmen potenziell 8–12 % Umsatzeinbußen kosten kann.
- Szenario: Die Lieferzeit ist nicht angegeben.
- Neues Ergebnis: Der Supply-Chain-Agent sieht null Tage.
Er wartet bis zur letzten Minute. Es gelingt ihm nicht, Materialien zu beschaffen. Er legt die Produktionslinie still. Oder schlimmer noch: Er berechnet eine Lieferzeit basierend auf einem branchenüblichen Durchschnittswert, der für Ihre spezielle Nischenlegierung nicht zutrifft.
Regel Nr. 1 von ERP-KI: Künstliche Intelligenz geht davon aus, dass Ihre Daten die Wahrheit sind.
Ihr fehlt der gesunde Menschenverstand, um zu erkennen, dass „Artikel A“ und „Artikel A-ALT“ dasselbe sind.
Die Wissenslücke der Stämme
Die größte Herausforderung für KI in ERP-Systemen besteht darin, dass das eigentliche Betriebsmodell oft in den Köpfen der Menschen existiert und nicht in den Datenbanktabellen.
- Explizite Daten: Was ist in Infor LN / M3 enthalten (Bestelldaten, Menge)?
- Implizite Daten: Lieferant X gibt 2 Wochen an, braucht aber immer 4 oder versendet niemals empfindliche Elektronik am Freitag.
Ein LLM (Large Language Model) kann keine Gedanken lesen.
Wenn ein Agent die Beschaffung steuern soll, müssen Sie implizites Wissen in explizite Daten.
Das bedeutet, dass Felder, die bisher „nice-to-have“ waren (wie Lieferantenbewertungen, genaue Lieferzeiten, Sicherheitsbestandslogik), nun obligatorisch.
Vektorisierung: Das Pflaster für unstrukturierte Daten
Es gibt aber auch einen Silberstreif am Horizont. Traditionelle ERP-Systeme hatten mit unstrukturierten Daten (PDF-Spezifikationen, E-Mail-Verläufe, Kommentarfelder) zu kämpfen.
Generative KI liebt unstrukturierte Daten. Durch einen Prozess namens Vektorisierung (Einbettung) können wir PDF-Handbücher und technische Daten in eine Vektordatenbank einspeisen. So kann ein Agent anhand der beigefügten PDF-Dateien die Frage beantworten: „Haben wir einen Motor, der mit diesen Spannungsspezifikationen kompatibel ist?“
Dies führt jedoch zu einem neuen Verwaltungsproblem: Sind veraltete PDFs in Ihrem Artikelstamm hinterlegt, empfiehlt die KI mit Sicherheit überholte Teile. Die Korrektheit Ihrer Dokumente ist nun genauso wichtig wie die Korrektheit Ihrer Zeilen und Spalten.
Der Fahrplan zur KI-Bereitschaft: Aufräumen oder aufgeben
Bevor Sie eine KI-Lizenz erwerben, benötigen Sie eine Datenstrategie. Laut MIT Sloan Management Reviewnur 24 % der Unternehmen als „datengetrieben“, was die enorme Diskrepanz zwischen Anspruch und Wirklichkeit verdeutlicht.
- Die Stammdatenbereinigung
kann die Bestandsoptimierung nicht gewährleisten, wenn dasselbe Lager unter drei verschiedenen Artikelnummern existiert.
Um dies zu beheben, müssen Sie die Artikelstammdaten und Geschäftspartnerdatensätze konsequent konsolidieren, damit die KI nur eine einzige, verlässliche Datenbasis erhält. - Anreicherung der Metadaten:
KI benötigt Kontext, um effektiv zu funktionieren.
Ein Code wie „Artikel 10202“ sagt einem LLM ohne aussagekräftige Beschreibungen nichts.
Um intelligente Funktionen zu ermöglichen, müssen Sie sicherstellen, dass Beschreibungen standardisiert, Attribute vollständig ausgefüllt und technische Klassifizierungen einheitlich angewendet werden. - mit der „Freitext“-Sucht!
Wichtige Anweisungen gehören nicht mehr in Textnotizen oder unstrukturierte Kommentare.
Geschäftslogik muss in strukturierte Felder verlagert werden, wo sie vom ERP-System und dem Agenten zuverlässig überprüft und umgesetzt werden kann, anstatt den Sinn hinter einer handschriftlichen Notiz zu erraten.
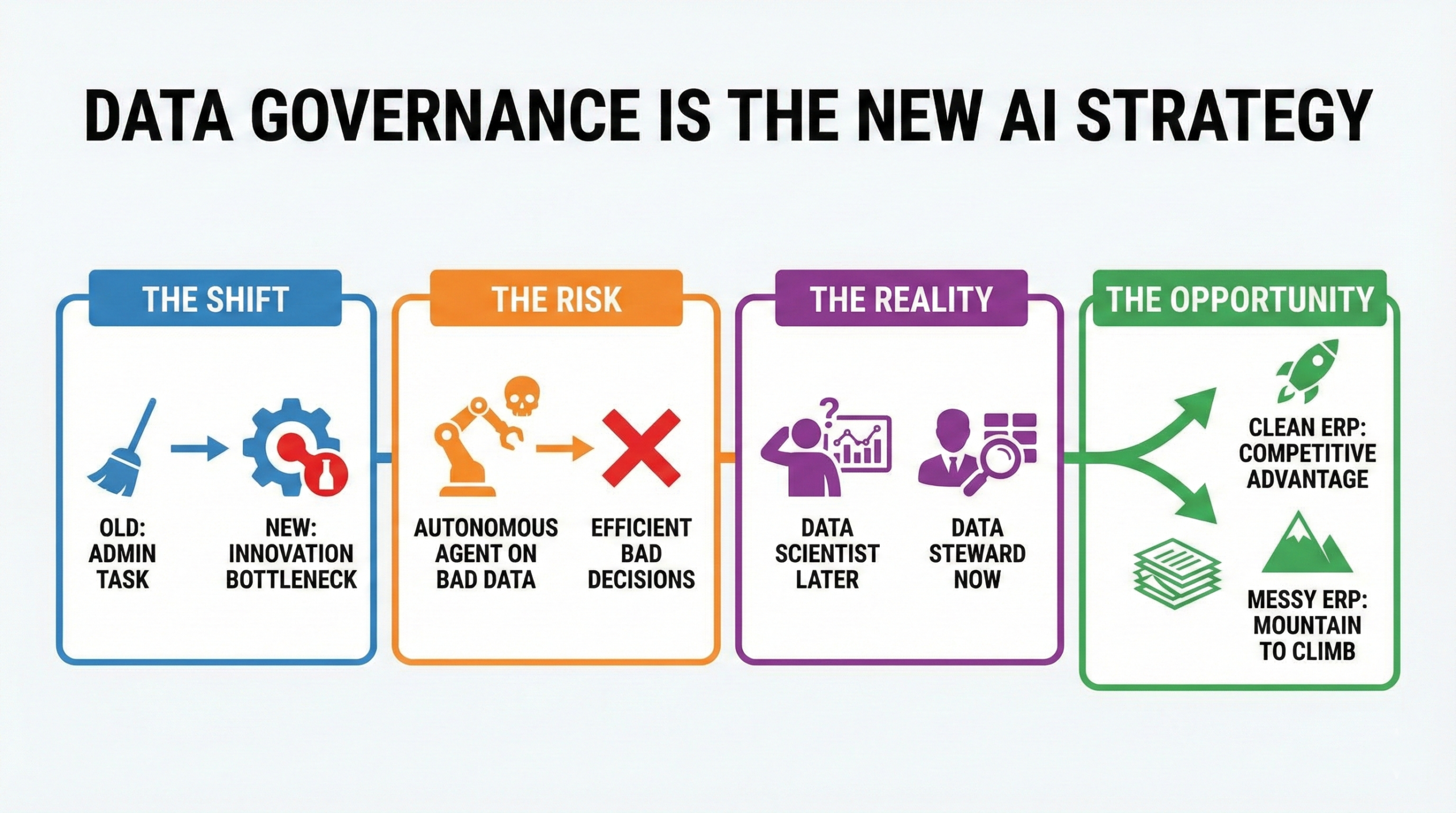
Die Entwicklung von Daten über Informationen zu Akteuren ist unausweichlich. Die Werkzeuge sind vorhanden, die Vision klar. Doch der Treibstoff für diesen Prozess ist Glaubwürdigkeit. Und Glaubwürdigkeit entsteht aus einer einzigen Quelle: der Genauigkeit der Aufzeichnungen.
Beginnen Sie mit der Reinigung.
Wichtigste Quellen & Weiterführende Literatur
- Gartner: Warum 85 % der KI-Projekte scheitern – Prognostiziert hohe Misserfolgsraten aufgrund fehlerhafter Daten, Voreingenommenheit oder Managementproblemen.
- Harvard Business Review: Datenbereitschaft für die KI-Revolution – 91 % der Führungskräfte sagen, dass eine zuverlässige Datengrundlage unerlässlich ist, aber nur 55 % vertrauen ihren aktuellen Daten.
- MIT Sloan: Das Potenzial von KI optimal nutzen – Kultur und Datenkompetenz werden als die größten Hindernisse für den Erfolg von KI identifiziert.
Als Nächstes: Wir haben die Technologie und (hoffentlich) die sauberen Daten. Doch was geschieht mit den Menschen? Im letzten Teil dieser Reihe beleuchten wir die menschliche Evolution: Warum der ERP-Experte von morgen die Dateneingabe aufgibt und mit der Algorithmenprüfung beginnt.
Verfasst von Andrea Guaccio
7. Januar 2026