L'IA tueuse : pourquoi les données corrompues ruineront votre agent

(Quatrième partie de la série : « L’évolution de l’intelligence ERP : des données aux agents »)
Dans la première partie, nous avons défini les termes.
Dans la deuxième partie, nous avons interrogé les données.
Dans la troisième partie, nous avons exploré les dangers liés aux agents autonomes.
Nous devons désormais faire face à la dure réalité qui anéantit jusqu'à 85 % des projets d'IA avant même leur lancement.
Ce n'est pas l'algorithme. Ce n'est pas la puissance du GPU. Ce sont vos données de référence.
Nous rêvons tous d'une entreprise autonome, mais posez-vous la question : utiliseriez-vous le pilotage automatique d'une voiture si les capteurs étaient couverts de boue et la carte GPS datait des années 1990 ?
C'est précisément ce que nous faisons lorsque nous appliquons l'IA générale à une base de données ERP obsolète, truffée de doublons, de délais manquants et À NE PAS UTILISER ».
L'effet multiplicateur « données erronées »
Dans le monde traditionnel des ERP, le principe « données erronées en entrée, données erronées en sortie » était un véritable fléau.
- Scénario : le délai de livraison indiqué dans le système est de 0 jour, mais le délai réel est de 30 jours.
- Ancien scénario : le système MRP suggère de commander trop tard.
Le planificateur le regarde, en rit, ignore le système et passe la commande manuellement en se basant sur son expérience. - Le filet de sécurité : l'humain constituait la couche de correction des erreurs.
Dans le monde de l'IA, ce filet de sécurité a disparu. Comme McKinsey dans son analyse de l'IA dans les chaînes d'approvisionnement, les modèles statistiques produisent des « résultats peu fiables » lorsque les données comportent des erreurs, ce qui peut entraîner pour les entreprises une perte de revenus de 8 à 12 %.
- Scénario : le délai de livraison est vide.
- Nouveau résultat : le responsable de la chaîne d’approvisionnement voit 0 jour.
Il attend la dernière minute. Il ne parvient pas à obtenir les matières premières. Il arrête la chaîne de production. Pire encore, il se fait une idée erronée du délai de livraison en se basant sur une moyenne générique du secteur qui ne s’applique pas à votre alliage spécifique et de niche.
Règle n° 1 de l’IA ERP : l’intelligence artificielle part du principe que vos données sont exactes.
Elle est incapable de comprendre que « Article A » et « Article A-ANCIEN » désignent la même chose.
Le déficit de connaissances tribales
Le plus grand défi pour l'IA dans les ERP est que le véritable modèle opérationnel réside souvent dans la tête des gens, et non dans les tables de la base de données.
- Données explicites : contenu dans Infor LN / M3 (dates des commandes, quantité).
- Données implicites : Le fournisseur X annonce 2 semaines, mais il en faut toujours 4 ou N'expédie jamais d'électronique sensible le vendredi.
Un modèle de langage étendu ( LLM ) ne peut pas lire dans les pensées. Si vous souhaitez qu'un agent gère les achats, vous devez convertir les connaissances implicites en données explicites . Cela signifie que les champs qui étaient auparavant considérés comme « utiles » (tels que les évaluations de performance des fournisseurs, les délais de livraison précis, la logique des stocks de sécurité) sont désormais obligatoires .
Vectorisation : le pansement sur une plaie pour les données non structurées
Il y a toutefois un aspect positif. Les ERP traditionnels avaient du mal à gérer les données non structurées (spécifications PDF, chaînes d'e-mails, champs de commentaires).
L'IA générative apprécie les données non structurées.
Grâce à un processus appelé vectorisation (intégration), nous pouvons intégrer des manuels PDF et des spécifications techniques dans une base de données vectorielle.
Cela permet à un agent de répondre à la question : « Disposons-nous d'un moteur compatible avec ces spécifications de tension ? » en lisant les fichiers PDF joints.
Cependant, cela engendre un nouveau casse-tête en matière de gouvernance : si vos fichiers PDF associés à votre fiche article sont obsolètes, l’IA vous recommandera sans hésiter des pièces dépréciées. La qualité de vos documents est désormais aussi importante que la clarté de vos données.
Feuille de route pour la préparation à l'IA : Nettoyer ou abandonner
Avant d'acheter une licence d'IA, il vous faut une stratégie de données. Selon la MIT Sloan Management Review, seulement 24 % des entreprises se définissent actuellement comme « axées sur les données », ce qui souligne l'écart considérable entre ambition et réalité.
- de déduplication des données de référence
ne peuvent pas optimiser les stocks si un même roulement est référencé par trois codes articles différents.
Pour remédier à ce problème, il est impératif de consolider les enregistrements des données de référence articles et des partenaires commerciaux afin de garantir que l'IA dispose d'une source unique de données fiables. - Enrichissez les métadonnées :
l’IA a besoin de contexte pour fonctionner efficacement.
Un code comme « Article 10202 » est incompréhensible pour un LLM sans descriptions détaillées.
Pour activer l’intelligence artificielle, vous devez vous assurer que les descriptions sont standardisées, que les attributs sont complets et que les classifications techniques sont appliquées rigoureusement de manière uniforme. - à l'utilisation excessive du texte libre ! Cessez
de consigner des instructions cruciales dans des notes textuelles ou des commentaires non structurés.
La logique métier doit être intégrée à des champs structurés où le système ERP et l'agent pourront la vérifier et agir en conséquence, plutôt que de devoir deviner le sens d'une note manuscrite.
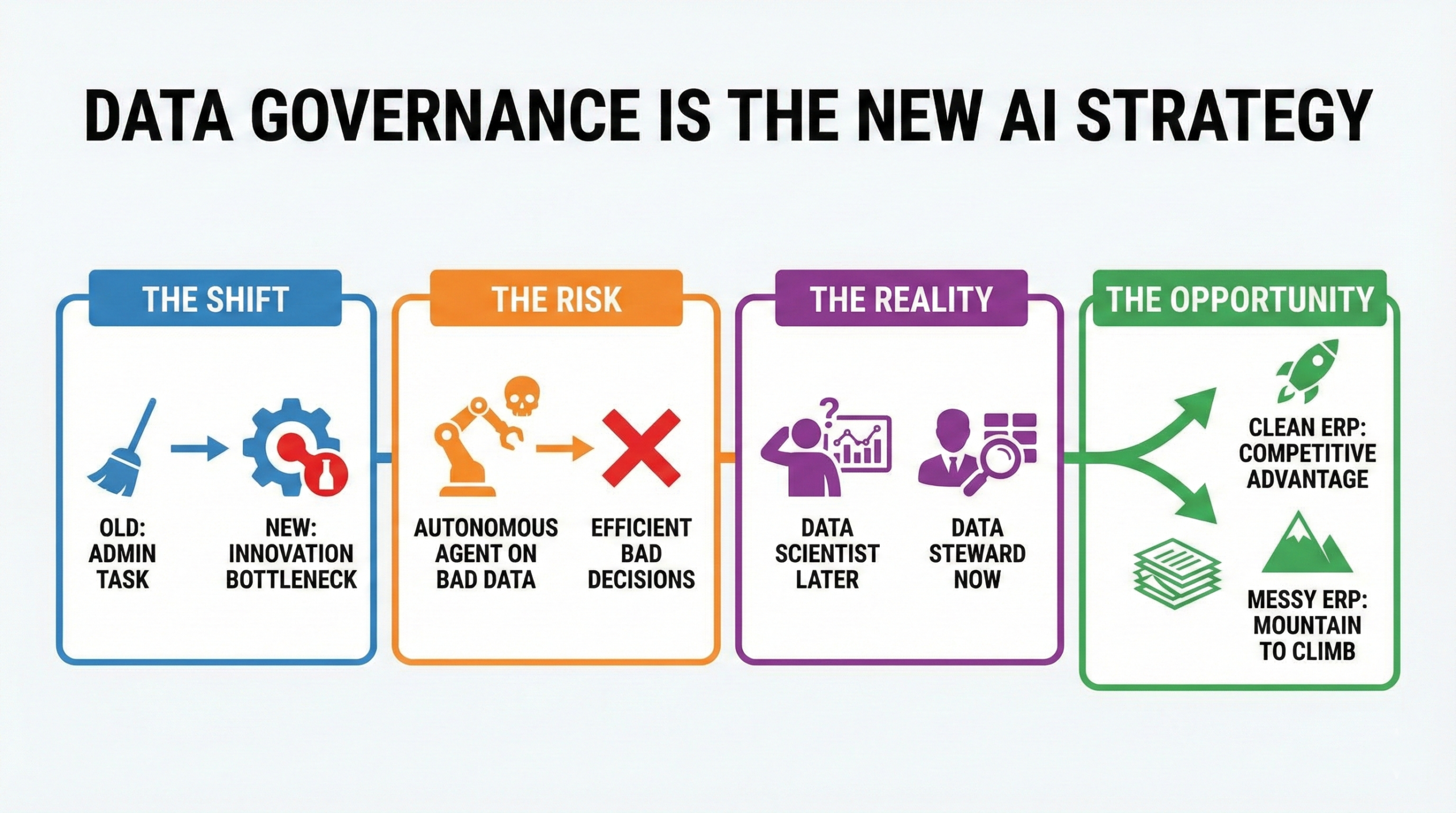
Le passage des données au renseignement, puis aux agents, est inévitable. Les outils existent et la vision est claire. Mais le carburant de cette machine, c'est la crédibilité. Et la crédibilité repose sur un seul pilier : l'exactitude des informations.
Commencez le nettoyage.
Sources clés et lectures complémentaires
- Gartner : Pourquoi 85 % des projets d’IA échouent – Prédit des taux d’échec élevés dus à des données erronées, à des biais ou à des problèmes de gestion.
- Harvard Business Review : Préparation des données à la révolution de l’IA – 91 % des dirigeants affirment qu’une base de données fiable est essentielle, mais seulement 55 % font confiance à leurs données actuelles.
- MIT Sloan : Tirer le meilleur parti de l’IA – Identifie la culture et la maîtrise des données comme les principaux obstacles au succès de l’IA.
Prochaine étape : nous disposons de la technologie et (espérons-le) de données fiables. Mais qu’adviendra-t-il des personnes ? Dans ce dernier volet de la série, nous explorerons l’évolution humaine : pourquoi l’ expert ERP de demain abandonnera la saisie de données pour se consacrer à l’audit des algorithmes.
Écrit par Andrea Guaccio
7 janvier 2026