Hoe rigide SQL-query's uw AI-hallucinaties voeden
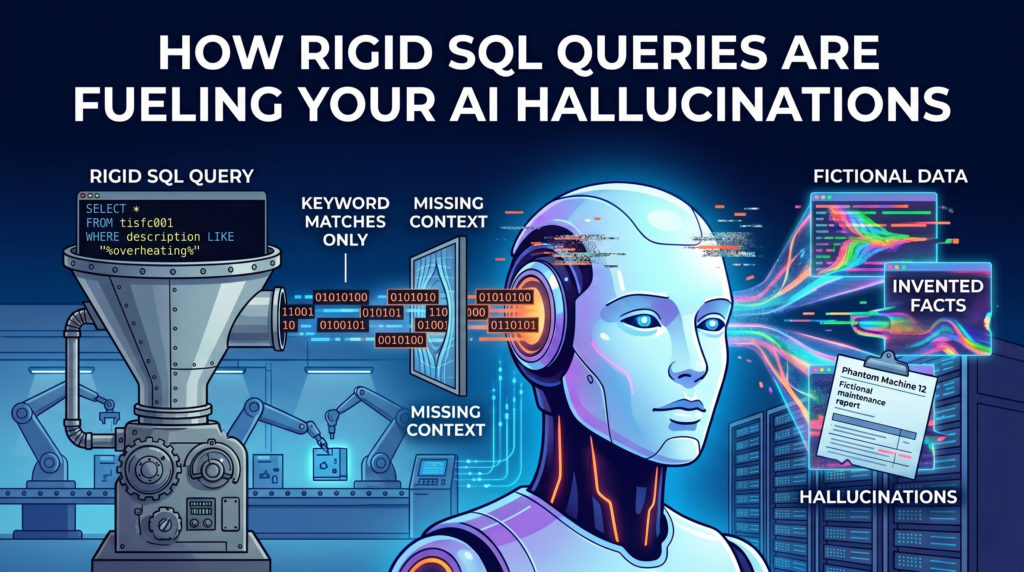
Je koppelt een geavanceerde AI aan je verouderde ERP-systeem en verwacht wonderen. In plaats daarvan liegt het systeem je recht in je gezicht voor. De echte boosdoener? Je raadpleegt nog steeds historische gegevens alsof het 2005 is.
Als ERP-consultant lees ik voortdurend over dit soort scenario's. Managers haasten zich om generatieve AI bovenop bedrijfssystemen te implementeren, in de hoop direct inzicht te krijgen in de context van gesprekken. Ze richten grote taalmodellen op oude data lakes en wachten op de resultaten.
Maar deze aanpak loopt meestal spaak zodra je de fabrieksvloer betreedt.
Als je probeert semantische betekenis te extraheren met behulp van rigide, op trefwoorden gebaseerde methoden om een moderne AI te voeden, vraag je praktisch om hallucinaties.
Laten we eens ontleden hoe we tegenwoordig bedrijfsdata opvragen en waar AI-ready architecturen daadwerkelijk naartoe gaan. Als we dit nu verkeerd aanpakken, kan dat uw hele AI-strategie in gevaar brengen.
De beperkingen van traditionele ERP-query's
Databases in systemen zoals Infor LN blinken uit in wat ze daadwerkelijk doen: precisie en transactionele integriteit.
Ze zijn ontworpen om specifieke regels snel en foutloos uit te voeren. Als je precies weet wat je zoekt, is klassieke SQL perfect. Wanneer je de exacte status van een specifieke productieorder nodig hebt, volstaat een eenvoudige SQL-instructie. Je richt je op de tabel tisfc001, koppelt de primaire sleutels en je haalt je exacte record op zonder ambiguïteit.
Maar historische analyses zijn zelden zo chirurgisch nauwkeurig.
Wanneer een supply chain manager vraagt: "Waarom zijn we consequent te laat met deze specifieke productlijn?", kan een standaard SQL-query daar niet direct antwoord op geven. Daarvoor is het nodig om handmatig vijf verschillende modules te koppelen binnen inkoop, magazijnbeheer en productie. Belangrijker nog, het vereist het interpreteren van ongestructureerde notities die door verschillende mensen in verschillende afdelingen zijn achtergelaten.
Stel je voor dat je een terugkerende machinestoring onderzoekt en kwaliteitsgebreken analyseert. Je schrijft een standaard SQL-query die zoekt naar 'WHERE description LIKE '%overheating%''. Je verouderde database zal braaf alleen exacte overeenkomsten retourneren.
Wat wordt er dan gemist? Al het andere. Het negeert volledig cruciale gegevens waarin een gehaaste operator aan het einde van zijn of haar dienst ' hoge temperatuur' , 'oververhit' of 'doorgebrande onderdelen' heeft ingetypt
Traditionele SQL mist semantisch begrip. Het ziet alleen rigide tekens. Wanneer je deze onvolledige, op trefwoorden gefilterde resultaten aan een AI-model voert, trekt het model conclusies op basis van een gefragmenteerde werkelijkheid. Dit is precies waar waardevolle zakelijke inzichten verloren gaan.
Het semantische voordeel
Als u historische gegevens wilt analyseren op zoek naar vage correlaties, biedt een vectordatabase een duidelijk structureel voordeel.
Datavectorisatie vertaalt menselijke tekst naar numerieke coördinaten, ook wel embeddings genoemd. Hierdoor worden gegevens gegroepeerd op basis van context en feitelijke wiskundige betekenis. Zie een embedding als een GPS-coördinaat voor een specifiek concept.
In plaats van letters te matchen, matcht de database de onderliggende betekenis. Als een planner ' vertraagd door leverancier' en een magazijnmedewerker ' wachten op onderdelen', ziet een klassieke SQL-query twee ongerelateerde problemen. Een gevectoriseerde database herkent dat het exact hetzelfde probleem is.
In een gevectoriseerde database worden de termen oververhitting en hoge temperatuur wiskundig direct naast elkaar geplaatst.
Door uw transactiegegevens over te zetten naar een vectorgebaseerde database zoals Google AlloyDB, stopt u met het matchen van tekenreeksen en begint u met het matchen van betekenis. Dit maakt meestal gebruik van stream-pipelines om gegevens veilig weg te halen uit de ERP-kern.
U krijgt de mogelijkheid om jarenlange historische gegevens op te vragen met behulp van natuurlijke taal. Het systeem begrijpt de bedoeling. Gebruikers hoeven geen complexe SQL-syntaxes meer te onthouden, door onduidelijke tabellen te navigeren of oude afkortingen te raden.
De juiste architectuur om mee te beginnen: RAG & Core Isolation
Je zou in de verleiding kunnen komen om generatieve AI direct toe te passen op je transactionele ERP-systeem. Doe dit niet. Het zal de operationele prestaties ernstig verslechteren en het risico met zich meebrengen dat je kernsysteem vastloopt.
LLM's zijn ongelooflijk zwaar. Als je een conversationele AI rechtstreeks op je live transactietabellen richt, leg je je dagelijkse werkzaamheden lam. De magazijnmedewerker die een vrachtwagen met goederen wil verzenden, zou niet hoeven te wachten op het systeem omdat een leidinggevende de AI vraagt om tien jaar aan onderhoudsgegevens te analyseren.
De moderne oplossing is gebaseerd op Retrieval-Augmented Generation (RAG) en kernisolatie. Een goed voorbeeld hiervan is de overstap van Infor van hun oude Coleman ML-systeem. Ze gebruiken momenteel LangChain om agents te bouwen die in staat zijn tot diepgaand semantisch redeneren, veilig verankerd in bedrijfslogica.
De RAG-workflow doorloopt doorgaans deze operationele stappen:
- Offloading: U streamt ERP-gegevens weg van de transactionele kern. Met behulp van tools zoals Infor Data Fabric stuurt u deze gegevens naar uw vectordatabase. Dit zorgt ervoor dat uw hoofdsysteem soepel blijft draaien.
- Ophalen: Een gebruiker stelt een vraag in natuurlijke taal. De AlloyDB-vectordatabase voert een snelle zoekopdracht uit om conceptueel relevante historische gegevens te vinden.
- Extractie: Alleen deze geldige records worden als referentie naar een extern, grootschalig taalmodel zoals Vertex AI gestuurd. Het taalmodel verwerkt deze gegevens en genereert een nauwkeurig antwoord zonder ooit het live ERP-systeem te hoeven raadplegen.
Deze RAG-workflow vormt momenteel de juiste basis voor elk AI-initiatief binnen een onderneming. Beschouw het echter als een startpunt, niet als een eindbestemming.
De industrie beweegt zich al richting Agentic Search: architecturen waarbij AI geen enkele statische semantische zoekopdracht uitvoert, maar in plaats daarvan autonoom bepaalt hoe en waar te zoeken. Het doorloopt meerdere zoekstrategieën (vectorzoekopdrachten, gestructureerde zoekopdrachten, bestandssystemen, kennisgrafieken) op basis van de complexiteit van de vraag.
Andrej Karpathy vestigde onlangs de aandacht op een verwant patroon: de LLM Wiki. Een AI-agent compileert ruwe brongegevens vooraf tot een gestructureerde, onderling verbonden kennisbank. In plaats van telkens tekstfragmenten op te halen, raadpleegt de agent een overzichtelijk en georganiseerd geheel dat hij al heeft opgebouwd, waardoor de intelligentie in de loop der tijd toeneemt.
Voor de meeste ERP-omgevingen is een goed opgezette RAG-pipeline tegenwoordig de juiste keuze. Maar de beperkingen van het contextvenster, die vector chunking noodzakelijk maakten, worden snel kleiner. Als u uw architectuur ontwerpt zonder een uitweg naar agentische patronen, zult u deze over achttien maanden alweer moeten bijwerken.
Het doden van hallucinaties
Een AI-hallucinatie treedt op wanneer een LLM (Logical Language Model) een output genereert die vloeiend en overtuigend is, maar feitelijk absurd. Deze modellen "kennen" geen feiten; ze voorspellen alleen waarschijnlijkheden op basis van hun onderliggende architectuur.
In complexe industriële omgevingen is een hallucinatie een kritieke mislukking. De AI zou vol vertrouwen een onderhoudsschema kunnen bedenken dat past bij een statistisch patroon, maar in werkelijkheid niet bestaat. Het zou bijvoorbeeld kunnen voorstellen om onderdelen te bestellen die tien jaar geleden uit productie zijn genomen, simpelweg omdat ze vaak in oude logboeken voorkwamen.
We kunnen hallucinaties niet wiskundig uitsluiten, maar we moeten ze wel terugdringen tot ze statistisch gezien irrelevant zijn. Hier zijn strikte regels die u moet naleven:
- Vereist strikte verankering: Dwing het LLM om uitsluitend te vertrouwen op de RAG-context die door uw vectordatabase wordt geleverd. Blokkeer expliciet de vooraf getrainde internetkennis om strikte verankering binnen de bedrijfsomgeving.
- Implementeer nultemperatuur: Stel de temperatuur van het model in op nul. Ontneem de AI de ruimte voor creativiteit om deterministische, zeer reproduceerbare resultaten te garanderen. We willen chirurgische precisie, geen creatief schrijven.
- Ontwikkel een verplichte terugvaloptie: Dwing het LLM-systeem door middel van rigoureuze prompt-engineering om "Gegevens niet gevonden" als het antwoord afhankelijk is van gegevens buiten de opgehaalde context.
- Geef prioriteit aan datakwaliteit: Al deze geavanceerde architectuur is zinloos als uw brondata waardeloos is. De ERP-data die naar de vectordatabase stroomt, moet schoon en genormaliseerd zijn.
Bruikbare inzichten voor IT-leiders
Laat je niet meeslepen door de hype. Het simpelweg aanschaffen van een AI-licentie lost een gebrekkige bedrijfsarchitectuur niet op. Als je ERP-systeem nu al een rommel is van ongestructureerde oplossingen, zal het invoeren ervan in een AI de verwarring alleen maar vergroten.
Combineer de transactionele precisie van uw ERP met het semantische begrip van een vectordatabase, en u maakt een einde aan het giswerk van de AI.
Begin met het beoordelen van de huidige datavolwassenheid voordat u AI-tools aanschaft. Evalueer hoe uw gebruikers momenteel problemen melden en of die beschrijvingen voldoende gestandaardiseerd zijn om effectief te kunnen worden gevectoriseerd.
Evalueer vervolgens Vector DB's voor historische analyse. Breng uw query-intenties in kaart en bescherm vooral uw kernsysteem door een ontkoppelde RAG-architectuur te bouwen. Ontwerp ten slotte met een exitstrategie. Bouw uw ophaallaag als een modulair component, niet als een monolithisch geheel. Wanneer agentische patronen volwassen zijn voor gebruik in de onderneming, moet u uw ophaalstrategie kunnen vervangen of uitbreiden zonder alles helemaal opnieuw te hoeven opbouwen.
Als uw ERP-systeem vandaag de dag nog steeds moeite heeft om basisgegevens van hoge kwaliteit te leveren, zal het toevoegen van semantische AI er alleen maar voor zorgen dat het systeem sneller faalt.
Als uw datafundament gebrekkig is, zal AI uw verwarring op grote schaal alleen maar vergroten. Herstel de architectuur voordat u de licentie aanschaft.
Geschreven door Andrea Guaccio
5 mei 2026