De AI-killer: waarom onzuivere data uw agent failliet kunnen laten gaan

(Deel 4 van de serie: “De evolutie van ERP-intelligentie: van data naar agents”)
In deel 1hebben we de termen gedefinieerd.
In deel 2hebben we de gegevens opgevraagd.
In deel 3hebben we de gevaren van autonome agenten onderzocht.
Nu moeten we de harde realiteit onder ogen zien die ervoor zorgt dat tot wel 85% van de AI-projecten voordat ze zelfs maar van start gaan.
Het ligt niet aan het algoritme. Het ligt niet aan de GPU-kracht. Het ligt aan je masterdata.
We willen allemaal een zelfrijdende onderneming, maar vraag jezelf eens af: zou je de autopilot in een auto inschakelen als de sensoren onder de modder zaten en de GPS-kaart uit 1990 stamde?
Dat is precies wat we doen als we GenAI loslaten op een verouderde ERP-database vol duplicaten, ontbrekende levertijden en ZONDER beschrijvingen.
Het "Garbage In"-multiplicatoreffect
In de traditionele ERP-wereld 'Garbage In, Garbage Out' een grote ergernis.
- Scenario: de doorlooptijd in het systeem is 0 dagen, maar de werkelijke doorlooptijd is 30 dagen.
- Oude uitkomst: MRP suggereert dat de bestelling te laat is.
De planner kijkt ernaar, lacht, negeert het systeem en plaatst de bestelling handmatig op basis van interne kennis. - Het vangnet: de mens fungeerde als foutcorrectielaag.
In de wereld van AI is dat vangnet verdwenen. Zoals McKinsey in hun analyse van AI in toeleveringsketens aangeeft, leveren statistische modellen "onbetrouwbare resultaten" op wanneer data fouten bevat, wat organisaties mogelijk 8-12% aan omzetverlies kan kosten.
- Scenario: de doorlooptijd is leeg.
- Nieuw scenario: de supply chain agent ziet 0 dagen.
Hij wacht tot het laatste moment. Hij slaagt er niet in materialen te bemachtigen. Hij legt de productielijn stil. Of erger nog, hij hallucineert een levertijd op basis van een algemeen industriegemiddelde dat niet van toepassing is op uw specifieke, niche-legering.
Regel #1 van ERP AI: Kunstmatige intelligentie gaat ervan uit dat uw gegevens waarheidsgetrouw zijn.
Het ontbreekt aan gezond verstand om te weten dat "Artikel A" en "Artikel A-OUD" hetzelfde zijn.
De kenniskloof binnen stammen
De grootste uitdaging voor AI in ERP is dat het daadwerkelijke operationele model zich vaak in de hoofden van mensen bevindt, en niet in de databasetabellen.
- Expliciete gegevens: wat staat er in Infor LN / M3 (PO-datums, hoeveelheid).
- Impliciete gegevens: Leverancier X zegt 2 weken, maar ze doen er altijd 4 weken over , of ze verzenden nooit gevoelige elektronica op vrijdag.
Een LLM (Large Language Model) kan geen gedachten lezen.
Als je wilt dat een agent het inkoopproces beheert, moet je impliciete kennis in expliciete gegevens.
Dit betekent dat velden die voorheen "wenselijk" waren (zoals leveranciersprestatiebeoordelingen, precieze levertijden, logica voor veiligheidsvoorraden) nu verplicht.
Vectorisatie: de pleister op de wond voor ongestructureerde data
Er is een lichtpuntje. Traditionele ERP-systemen hadden moeite met ongestructureerde data (pdf-specificaties, e-mailconversaties, commentaarvelden).
Generatieve AI is dol op ongestructureerde data.
Via een proces genaamd vectorisatie (embedding) kunnen we PDF-handleidingen en technische specificaties in een vectordatabase invoeren.
Hierdoor kan een agent de vraag beantwoorden: "Hebben we een motor die compatibel is met deze spanningsspecificaties?" door de bijgevoegde PDF-bestanden te lezen.
Dit leidt echter tot een nieuwe beheersnachtmerrie: als u verouderde pdf's aan uw artikelstamgegevens hebt gekoppeld, zal de AI vol vertrouwen verouderde onderdelen aanbevelen. De netheid van uw documenten is nu net zo belangrijk als de netheid van uw rijen en kolommen.
De routekaart naar AI-gereedheid: opruimen of opgeven
Voordat je een AI-licentie koopt, heb je een datastrategie nodig. Volgens MIT Sloan Management Reviewslechts 24% van de bedrijven zichzelf momenteel als 'datagedreven', wat de enorme kloof tussen ambitie en realiteit benadrukt.
- voor het verwijderen van dubbele stamgegevens
kunnen de voorraad niet optimaliseren als hetzelfde lager in drie verschillende artikelcodes voorkomt.
Om dit op te lossen, moet u de artikelstamgegevens en de records van de zakenpartners grondig consolideren, zodat de AI één 'enkele versie van de waarheid' ziet. - Verrijk de metadata.
AI heeft context nodig om effectief te functioneren.
Een code zoals "Artikel 10202" betekent niets voor een LLM zonder uitgebreide beschrijvingen.
Om intelligentie mogelijk te maken, moet u ervoor zorgen dat beschrijvingen gestandaardiseerd zijn, attributen volledig zijn ingevuld en technische classificaties strikt worden toegepast. - met het gebruik van vrije tekst.
Plaats geen cruciale instructies meer in tekstnotities of ongestructureerde opmerkingen.
Bedrijfslogica moet worden verplaatst naar gestructureerde velden waar de ERP-logica en de agent deze betrouwbaar kunnen controleren en erop kunnen reageren, in plaats van te moeten gissen naar de bedoeling achter een handgeschreven notitie.
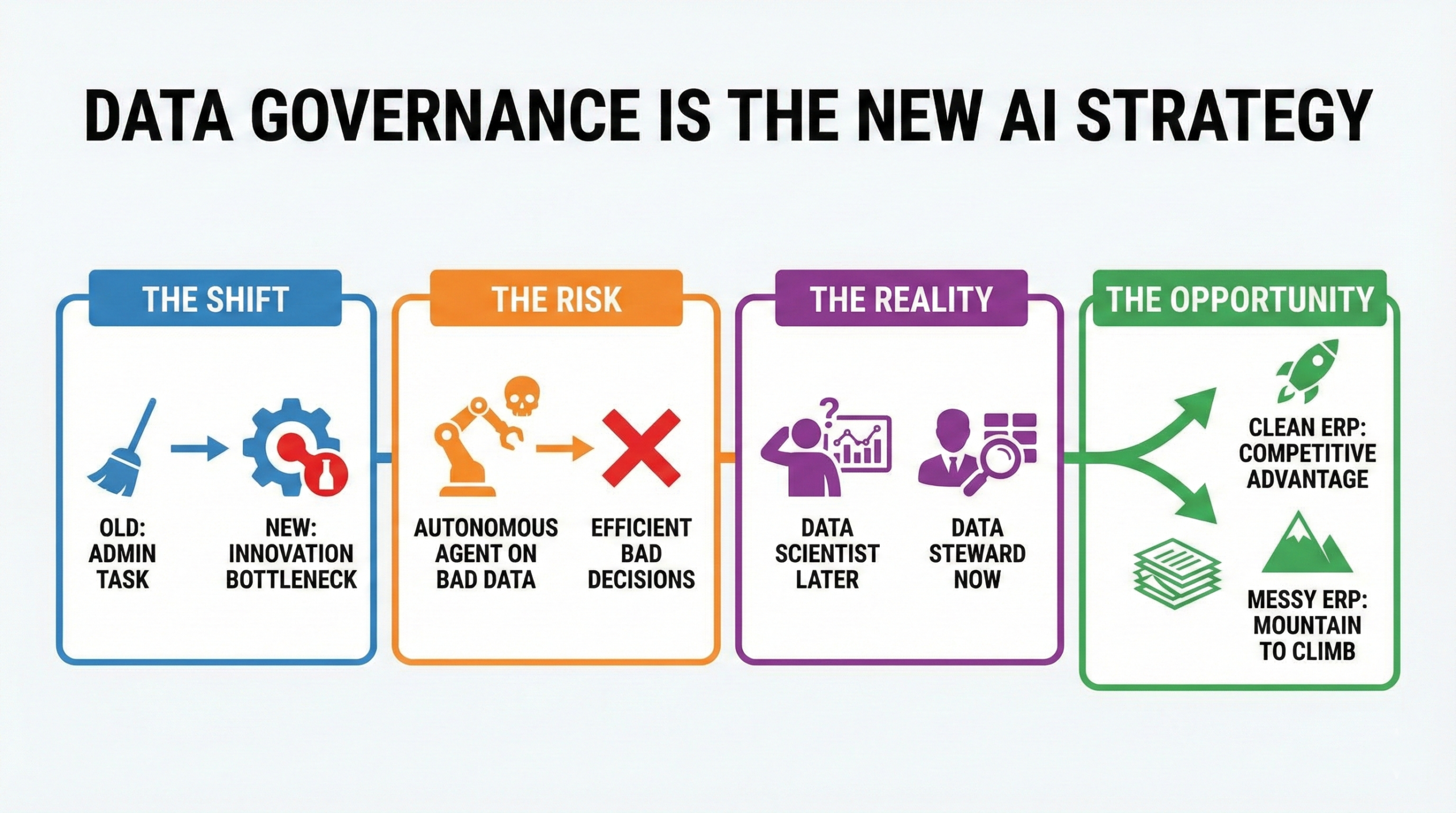
De evolutie van data naar intelligentie naar agenten is onvermijdelijk. De tools zijn er en de visie is helder. Maar de brandstof voor deze motor is geloofwaardigheid. En geloofwaardigheid komt van één bron: de nauwkeurigheid van de gegevens.
Begin met schoonmaken.
Belangrijke bronnen en verder lezen
- Gartner: Waarom 85% van de AI-projecten mislukt – Voorspelt hoge mislukkingspercentages als gevolg van onjuiste gegevens, vooringenomenheid of managementproblemen.
- Harvard Business Review: Data gereedheid voor de AI-revolutie – 91% van de leiders zegt dat een betrouwbare datafundament essentieel is, maar slechts 55% vertrouwt hun huidige data.
- MIT Sloan: Het maximale uit AI halen – Identificeert cultuur en data-geletterdheid als de belangrijkste obstakels voor het succes van AI.
Volgende stap: we hebben de technologie en (hopelijk) de schone data. Maar wat gebeurt er met de mensen? In het laatste deel van deze serie onderzoeken we de menselijke evolutie: waarom de ERP-expert van morgen stopt met data-invoer en begint met algoritme-audits.
Geschreven door Andrea Guaccio
7 januari 2026